Desde la adopción generalizada de las computadoras en los negocios hace más de cincuenta años, ha habido una necesidad de que las compañías integrasenn datos de diferentes sistemas para propósitos como informes, análisis o desarrollo de aplicaciones. En los últimos años, con la adopción generalizada de aplicaciones móviles y sobre todo la adopción Cloud, las empresas se encontraron apoyando una cantidad cada vez mayor de fuentes de datos (silos) y formatos dispares. Keith Block, COO de Salesforce, mencionó recientemente:
"El 90% de los datos mundiales se crearon en los últimos 12 meses".
Ante las demandas de la administración, los usuarios y las autoridades reguladoras de informar o acceder a esta información dispar de manera unificada, los departamentos de IT a menudo adoptaron el enfoque expedito de escribir código o usar conectores para integrar las fuentes de datos dispares requeridas y responder a estas solicitudes. Por ejemplo un informe o una aplicación particular es un ejemplo popular, donde a menudo se siguen agregando solicitudes de datos adicionales. Esto se traduce en un significativo incremento de mano de obra adicional, que consume mucho tiempo, resultando en un drenaje excesivo de los recursos TI. Abrumados por estas numerosas demandas, los departamentos de TI a menudo consideraron necesario retrasar la respuesta, creando un retraso que resultó en una cantidad de interesados cada vez más frustrada.
Una solución que surgió a principios de la década de 1990 fue el data warehouse: un repositorio central de datos construido a partir de fuentes de datos dispares de negocio. Esto representaba una arquitectura estrechamente unida ya que todos los datos dispares se almacenaban físicamente y se reconciliaban en un repositorio. Con una sola fuente de datos integrados, fue mucho más fácil para TI satisfacer las necesidades de informes de la empresa. A pesar de lo significativo de este avance, se ponen de manifiesto las deficiencias del enfoque del data warehouse:
- La creación de un almacén de datos requiere grandes gastos para configurar lo que es una base de datos relacional enorme, física y redundante. Un componente principal de este proceso fue extraer, transformar y cargar ("ETL") los datos de las fuentes de datos heterogéneos en el almacén de datos.
- Se necesitó tiempo y recursos de TI significativos para cuidar y alimentar un data warehouse. Si las fuentes de datos se actualizaban con frecuencia, el proceso de ETL debía volver a ejecutarse regularmente para mantener sincronizados los datos en el data warehouse.
- No todos los datos de una empresa se almacenaron en el almacén de datos. Si un informe exigía una nueva fuente de datos, se requería que el departamento de TI dedicara tiempo para integrarlo en el almacén de datos.
- Los datos contenidos en un data warehouse no estaban disponibles en tiempo real, lo que afectó la velocidad y la calidad de la decisión al aprovechar esos datos. El retorno de los datos extraídos de un data warehouse solo estaba actualizada como la última vez que se actualizaron los datos del almacén.
La virtualización de datos surgió como una tecnología para abordar las deficiencias de la codificación manual y la tecnología de almacenamiento de datos para acceder a los datos de fuentes de datos dispares de una manera integrada.
¿Que es la virtualización de datos?
La tecnología de virtualización de datos está ganando impulso rápidamente y está mejorando radicalmente la productividad de los usuarios y desarrolladores para acceder a las fuentes de datos distribuidos de su compañía para la integración de datos, creación de informes y análisis, y desarrollo de aplicaciones. Es un método ágil que permite el acceso en tiempo real a fuentes de datos dispares en toda la empresa (en las instalaciones y en cloud) en una fracción del tiempo y a una fracción del coste de los enfoques tradicionales. Para aquellos que no estén familiarizados con el término, la siguiente es una definición estándar para la virtualización de datos:
"La virtualización de datos extrae datos de múltiples fuentes dispares creando una capa de datos virtual unificada que proporciona a los usuarios un fácil acceso a los datos fuente subyacentes".
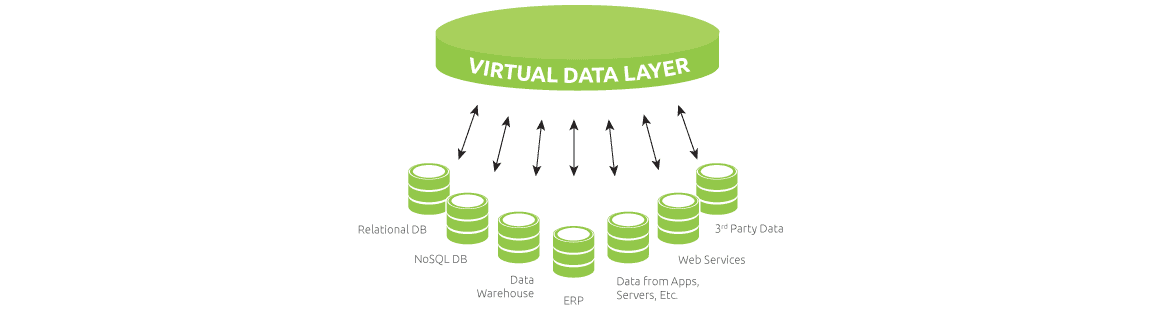
Para acceder a los datos, un usuario (que puede ser una persona o un programa ) consulta la base de datos virtual y maneja la recuperación de los datos requeridos de las fuentes de datos. Es importante destacar que esta arquitectura débilmente acoplada significa que no hay necesidad de copiar o replicar datos de cada fuente de datos constituyentes a un repositorio como con el almacenamiento de datos. La virtualización de datos brinda la capacidad de transformar las fuentes de datos subyacentes en formas unificadas que los usuarios pueden consumir. También ofrece la capacidad de crear, actualizar o eliminar información en las fuentes de datos en tiempo real.
El primer paso es modelar las fuentes de datos seleccionadas para formar parte de la capa de datos virtual en un repositorio de metadatos. Esto significa que la ubicación de las tablas, el tipo de uniones, la seguridad y otras partes clave de información se asignan desde cada origen de datos a un repositorio de metadatos (esencialmente un almacén que almacena conocimientos importantes sobre las fuentes de datos.) El repositorio de metadatos resultante representa efectivamente el ADN de los datos de una compañía y es un mapa detallado sobre cómo localizar todos los datos subyacentes a la capa de datos virtual.
Desde aquí, el motor de consulta entra en juego. Cuando se realiza una consulta de datos específicos a la capa de datos virtual, se pasa al motor de consulta que lo alimenta con la información clave extraída del repositorio de metadatos. Esto crea una consulta transformada que tiene la inteligencia incrustada (ubicación, seguridad, lógica comercial, auditoría, etc.) para recuperar los datos requeridos de las fuentes de datos subyacentes. El motor de consultas tiene la capacidad de manejar sin problemas las consultas que requieren recopilar datos de dos o más orígenes de datos dispares al unirlas, en tiempo real, en un único conjunto de resultados para que el usuario final parezca como si tratara con una base de datos virtual. El resultado final es que, desde la perspectiva del usuario, la capa de datos virtual proporciona un acceso sin interrupciones a los datos subyacentes como si fuera una base de datos virtual sin necesidad de lidiar con la complejidad de integrar cada fuente de datos. De hecho, un desarrollador ni siquiera necesita saber dónde están almacenados o ubicados los datos.
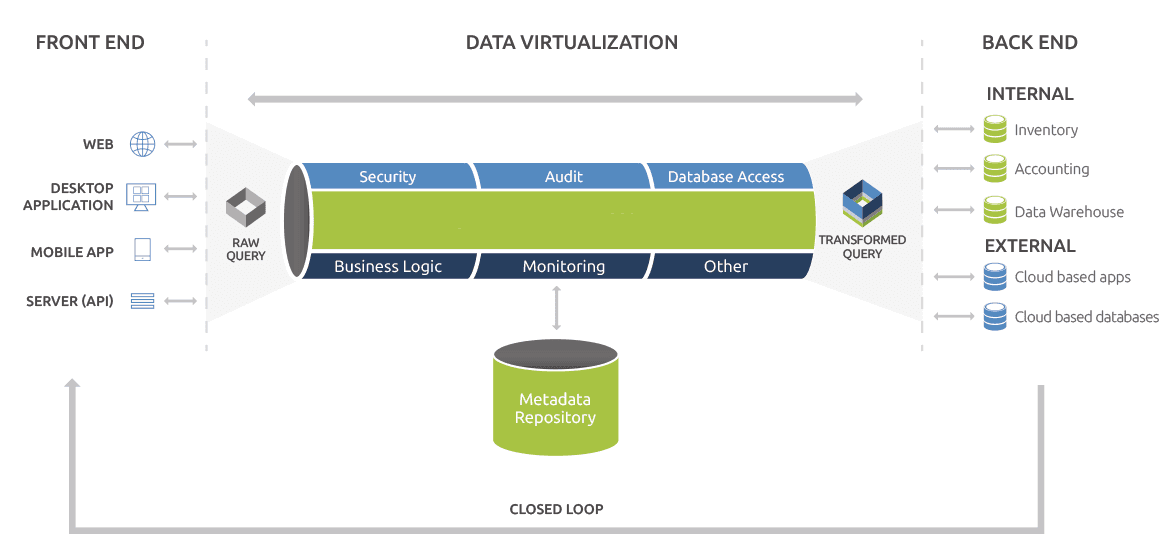
Virtualización de datos VS enfoques tradicionales para la integración de datos
Un ejemplo de integración de datos sería una empresa que desea mejorar el valor derivado del aprovechamiento de su aplicación CRM utilizada por sus representantes de servicio al cliente para gestionar e interactuar con los clientes. Quiere agregar datos importantes de su aplicación de automatización de marketing y nueva aplicación de marketing en redes sociales, de modo que los representantes puedan tener una visión más integral de un cliente al hablar con ellos. Las discusiones que siguen exploran las diferencias entre el enfoque tradicional de escribir el código y los conectores necesarios para lograr la integración y el uso de la vitalización de datos.
El enfoque tradicional sería la codificación manual. Esto requeriría el seguimiento de un desarrollador:
- Familiarizarse con el modelo de datos de cada fuente de datos.
- Ser experto en el entorno de desarrollo de cada aplicación (es decir, Ruby on Rails, .Net, Java, etc.)
- Para escribir código que integra cada nueva aplicación a la aplicación existente. Esto incluiría el modelado de datos para determinar la forma óptima en que se integrarán las tres fuentes de datos. También requeriría tener en cuenta consideraciones tales como el formato, la seguridad, la lógica comercial, etc. para integrar correctamente cada fuente de datos.
- Para probar e implementar el código desarrollado y asegurarse de que esté libre de errores y cumpla con los requisitos.
El enfoque de codificación manual funciona claramente y representaría una relación cableada entre las aplicaciones. Sin embargo, hay ciertas deficiencias:
- Como se describió anteriormente, para integrar correctamente estas dos aplicaciones mediante codificación manual, se requieren cantidades significativas de tiempo y habilidad por parte de un desarrollador.
- Si es necesario agregar o eliminar una nueva fuente de datos en el futuro, será necesario volver a codificarla y volver a probarla y consumirá tiempo adicional de desarrollador para implementarla. Es esta inversión requerida en el tiempo lo que lleva a que las iniciativas se retrasen y atrasen las TI. No es de extrañar que, por lo general, el 80% del tiempo y el gasto de TI se dediquen a "abrir la tienda" frente a trabajar para mejorar el negocio.
- La integración codificada a mano es frágil, lo que significa que es probable que se rompa cuando haya cambios / actualizaciones en el futuro de cualquier software al que esté conectado. Donde el aumento del tiempo de inactividad se convierte en una frustración para los usuarios.
- Para manejar la seguridad, se requeriría unificar la seguridad de cada aplicación con un modelo de seguridad ad hoc que un desarrollador puede o no tener la habilidad y el tiempo para hacerla robusta. La codificación manual crea muchos caminos entre la aplicación existente y las aplicaciones que se integran. Más vías equivalen a más posibilidades de errores de seguridad.
- Si hay un error y la aplicación se rompe, todo lo que se producirá es un error de ejecución. No habrá identificación del tipo de error o su ubicación. Un desarrollador tendrá que trabajar a través de muchas capas (registros del sistema, datos brutos, etc.) en diferentes aplicaciones para resolver el problema antes de poder curarlo. Si el desarrollador que escribió el código no ha proporcionado la documentación adecuada o ha abandonado la empresa, esto se vuelve aún más problemático.
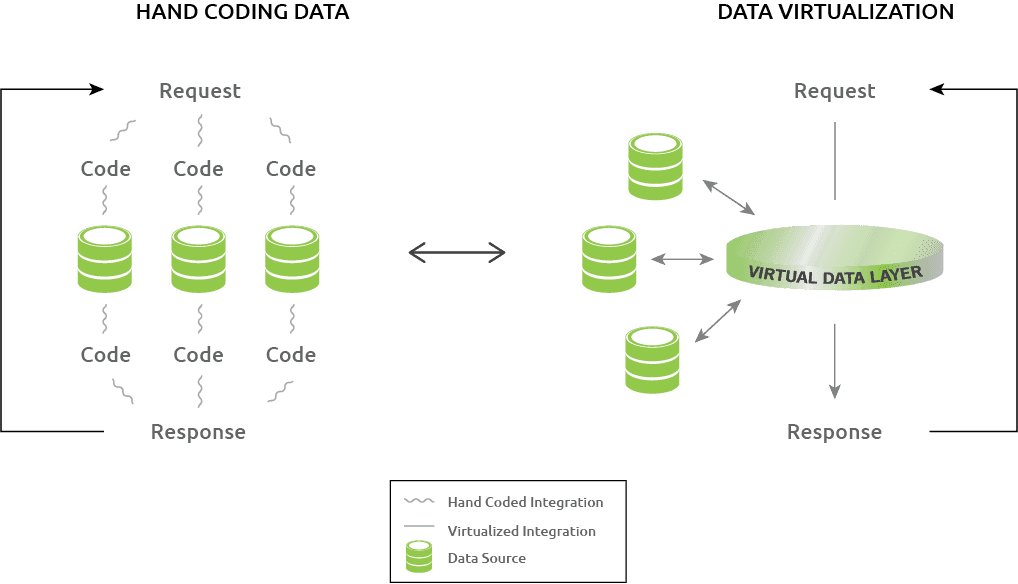
Alternativamente, con la virtualización de datos, las bases de datos que subyacen tanto a la automatización del marketing como a las aplicaciones de redes sociales se modelarán e incluirán esto en la capa de datos virtual. Una capa de datos virtual superior podría completarse en días. La capa final de datos virtuales requiere trabajar con los administradores para determinar cómo quieren modelar los datos. La aplicación de servicio al cliente existente se integrará con la capa de datos virtual, lo que permitirá recuperar datos de cada una de las aplicaciones. Esto tiene múltiples beneficios, tales como:
- Integración fácil: No es necesario tratar con las complejidades y la carga de trabajo de la codificación manual como se describió anteriormente. Si los requisitos de la aplicación cambian y se necesitan nuevas fuentes de datos, la capa de datos virtuales puede acceder rápidamente a ellos sin volver a escribir el código.
- Estabilidad mejorada: Una capa de datos virtual puede adaptarse a los cambios en el software que ocurren de forma natural a lo largo del tiempo debido a cosas tales como el lanzamiento de nuevas versiones.
- Mejor identificación de errores y cambios: Una capa de datos virtual proporciona notificaciones específicas de errores o cualquier cambio en sus fuentes de datos. Esto incluye la descripción de la naturaleza y ubicación del cambio. Permitiendo que un programador identifique y resuelva rápidamente un problema al hacer que una aplicación vuelva a funcionar más rápido.
- Seguridad superior: La capa de datos virtual proporciona un solo punto de acceso a todas las fuentes de datos subyacentes y recupera datos directamente de una fuente de datos sin necesidad de tocar varias capas de middleware como con la codificación manual. El acceso de los usuarios se puede controlar estrictamente en grano fino o grano grueso. Autenticación, autorización y capacidades de auditoría estarian todas incluidas.
- Enfoque estándar: La virtualización de datos requiere un proceso estructurado para integrar los datos. Esto significa código consistente y la capacidad de depurar de manera efectiva. También toma la variabilidad del estilo de programación de cada desarrollador fuera de la ecuación.
- Validación del sistema: En caso de que se produzcan cambios en el esquema de las fuentes de datos, los cambios de esquema se pueden validar proactivamente con la capa de datos virtual. El componente de validación informa sobre cualquier característica que ya no funciona.
- Ahorro significativo: Por todas las razones mencionadas anteriormente, se puede ahorrar mucho dinero y tiempo de desarrollador utilizando la virtualización de datos. Los ahorros se acumulan no solo en la configuración inicial sino en el mantenimiento continuo. Algunas empresas han experimentado ahorros estimados en más del 80% en comparación con los enfoques tradicionales.
Beneficios exponenciales al integrar múltiples fuentes de datos:
Existe un argumento de peso para la integración de una codificación única y simple de fuente de datos siendo el mejor enfoque. Con un programador experto, puede hacerse de forma rápida y rentable. Sin embargo, a medida que crece la cantidad de fuentes de datos que deben integrarse y aumenta su complejidad, existen claras ventajas para el uso de la virtualización de datos, ya que todos los beneficios mencionados anteriormente crecen exponencialmente. Es importante destacar que también proporciona una arquitectura muy clara y comprensible en comparación con la codificación manual que puede convertirse rápidamente en un laberinto de código frágil e inmanejable si no se gestiona correctamente.
Conclusión
En conclusión, a medida que las fuentes de datos crecen y se vuelven más complejas dentro de cada empresa, los viejos enfoques para integrar y acceder a los datos están llegando a un muro de rendimiento. La virtualización de datos puede abstraer los datos de los sistemas fuente, lo que permite construir fácilmente una capa de datos virtual compuesta de todas las fuentes de datos. Esto agiliza en gran medida la capacidad de una compañía de acceder y consumir sus datos, al tiempo que ahorra tiempo y dinero considerables. Sin duda, es un enfoque que todo departamento de TI debe considerar seriamente.