En este artículo intentaré explicar de la manera más sencilla posible cómo detectar anomalías en base al número de logins fallidos producidos en el AD usando Splunk. Como muchos sabréis, Splunk es el correlador de moda dentro de la seguridad. Mediante el análisis de series temporales, y usando el comando predict, podremos modelar el comportamiento esperado del número de logins fallidos y generar una alerta cuando la cifra no cuadre con los parámetros esperados. ¿Por qué el número de logins fallidos? Porque si “los malos” intentan realizar un ataque de fuerza bruta contra algún servicio que haga uso de credenciales de dominio, lo más normal será ver un incremento del número de logins.
Primera aproximación
Si pudiésemos representar el número de logins fallidos de nuestra empresa (una empresa grande) veríamos algo similar a esto:
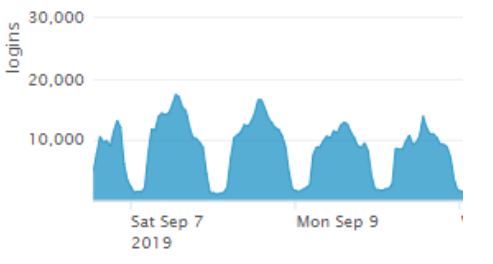
Se puede pensar que la forma más sencilla de hacerlo sería definir un umbral fijo y cuando detectemos que el número de logins fallidos es mayor que este, generar una alerta. La pregunta es, ¿dónde ponemos ese umbral? ¿En 20000 eventos cada hora siguiendo el ejemplo anterior? Esto daría margen a que los malos pudieran realizar ataque de fuerza bruta por la noche sin que nos enterásemos. ¿Y si lo ponemos en 5000 eventos cada hora para tener visibilidad por la noche? Sí, exacto, es justo lo que estáis pensando… tendríamos un volumen de falsos positivos intratable.
Se impone la necesidad de generar un método de trabajo que sea capaz de adaptarse a estas variaciones. Hay varios métodos como la aproximación estadística usando la variación estándar del acumulado en el tiempo, usar series temporales, etc. En este artículo usaremos (como habréis adivinado) la aproximación de series temporales con las herramientas que nos ofrece Splunk.
Series temporales y su aplicación
En este apartado definiremos qué son las series temporales y cómo podemos usarlas. Como el fin de este artículo es poder predecir el número de logins fallidos que se van a producir en nuestra compañía, y dado que suelen tratarse de comportamientos periódicos, parece tener cierto sentido analizar el número de logins fallidos con series temporales. ¿Por qué? Al final, durante las horas laborales veremos un mayor número de logins fallidos que durante la noche.
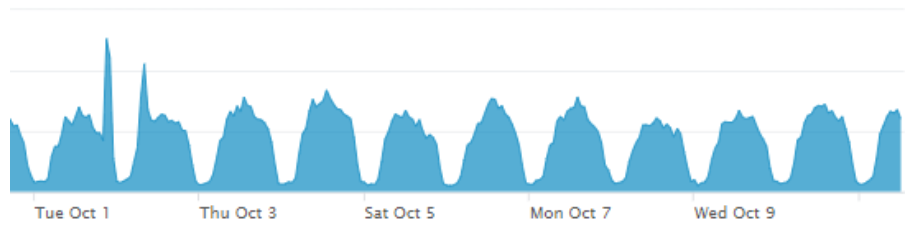
Esta repetición, más o menos constante, es lo que se denomina estacionalidad. Durante el día (pico) hay más logins que durante la noche (valles). Esta propiedad será muy importante en este artículo ya que permitirá facilitar la intendencia de la detección. Además, se puede observar que los valores son más o menos idénticos durante los días; esta propiedad se denomina autocorrelación. En palabras sencillas significa que los bloques de información que manejamos son más o menos iguales en amplitud y periodicidad. Existen otras propiedades como son la estacionariedad que permite medir si la media y la varianza son más constantes durante el tiempo; es una extensión de las anteriores propiedades.
Usando series con Splunk
Splunk tiene comandos que permiten realizar la tarea de identificar y predecir dichos patrones. En un alarde de originalidad, los desarrolladores de Splunk han llamado a este comando “predict” :O . Este comando permite recibir varios parámetros de entrada. Intentaré explicarlos de la manera más sencilla y breve posible.
- Field-list. Es el campo a predecir. El nombre de la variable que queremos predecir. Se pueden introducir varios campos si el algoritmo elegido lo permite.
- Algorithm. El tipo de algoritmo que usaremos para predecir los datos. Existen varios y cada uno tiene una aplicación diferente.
- Algoritmo LL (Local level) : No es válido para conjuntos de datos que sean estacionarios o estacionalidad. Es el más simple.
- Algoritmo LLT (Local level trend) : Permite realizar predicciones para conjuntos de datos que tenga tendencia, pero no estacionalidad.
- Algoritmo LLP (Seasonal local level) : Este método permite predecir valores con estacionalidad. Tiene en cuenta la regularidad cíclica de los datos. Se le puede indicar la periocidad de los datos a predecir.
- Algoritmo LLP5 (Combines LLT and LLP models for its prediction) : Este algoritmo permite predecir dos variables. Una usando LLP y otra usando LLT. Después se calcula la media de ambos que será el resultado final.
- Algoritmo LLB (Bivariate local level) : Es un método bivariante sin estacionalidad ni tendencia. Usa dos datasets para realizar predicciones sobre el otro dataset.
- Algoritmo BiLL (Bivariate local level) : Un método bivariante que permite predecir dos series temporales a la vez. La covarianza de ambas series es tenida en cuenta.
- Correlate. Especifica la serie temporal que el algoritmo LLB usará para predecir otra serie temporal. Sólo aplica si se usa LLB.
- Future_timespan. Especifica cuantas predicciones futuras se van a computar.
- Holdback. Especifica el número de datos desde el final que no se van a usar para realizar la predicción. Si se usa junto a future_timespan se pude usar para determinar la precisión de la configuración realizada.
- Period. Especifica la longitud de los periodos de las series temporales.
Podéis encontrar más información sobre todos estos puntos en la documentación oficial de Splunk . Cabe destacar que los intervalos de confianza de Splunk están configurados por defecto al percentil 95 .
Pintando datos en Splunk
Para poder extraer los datos necesitamos pintar los logins. Como aquí somos gente ordenada tenemos todos los datos en CIM. Además, los datos están acelerados (no, no es que vayan de speed sino que están cargado en memoria). Todo esto permite realizar búsquedas de mucho tiempo de manera rapidísima. Bueno, sin más dilación, la búsqueda tendría esta pinta:
| tstats count FROM datamodel=Authentication summariesonly=true where Authentication.action="failure" by Authentication.action, _time span=1h
| timechart values(count) AS logins span=1
Básicamente contamos el número de fallos de autenticación en periodos de 1 hora y denominamos a esta variable logins. Básicamente cuenta en número de intentos fallidos de login que hay cada hora desde el momento de inicio que le indiquemos y lo guarda en una caja. Así pues, tendríamos algo de este estilo:

Mmmm… no parece muy intuitivo, mejor pintarlo en modo gráfico que se verá mejor ¿no? Además, podremos ver dónde están los picos no deseados.

Está claro que ha habido momentos raros en los que han ocurrido picos que no tenían ningún sentido. ¿Podremos detectarlos con nuestro algoritmo? Bien, para ver si esto es posible vamos a usar el algoritmo LLP, que si os acordáis era aquel que tiene en cuenta la recursividad cíclica y estacionalidad de los datos. (Nota al lector. No es que yo sea muy listo y sepa qué algoritmo tengo que usar según veo los datos, sino que he ido probando y este es el que mejor resultado me ha dado)
| tstats count FROM datamodel=Authentication summariesonly=true where Authentication.action="failure" by Authentication.action, _time span=1h
| timechart values(count) AS logins span=1h| timechart values(count) AS logins span=1h
| predict logins as prediction algorithm=LLP future_timespan=30 holdback=11
| where prediction!="" AND logins!=""
| eval residual = prediction - logins| eval residual = prediction - logins
Este sería el comando que nos permite realizar una buena predicción en el caso de los datos que yo estoy usando. El comando “predict” ya se ha explicado más arriba. El comando “where” elimina las predicciones o números de login que estén vacíos. Por último, calculamos la diferencia entre los predichos y los logins reales. Si el número es negativo significa que ha habido un incremento de los logins respecto a lo esperado/predicho y viceversa. Además, Splunk también te ofrece un intervalo de confianza (recordemos que es el percitil95 tanto por arriba como por debajo del valor predicho).
Cada dataset y cada caso son particulares. Se deberá probar qué valores son los que mejor se ajustan a este a fin de encontrar la mejor predicción. Por ejemplo, podéis jugar con el tiempo de agregación de datos; en lugar de usar 1h probad con 10 min, 30 min, 2 horas…. 24 horas. Esto os dará curvas más suaves o abruptas. Cuanto más suaves sean las gráficas, más fácil será para el modelo predecir los valores, pero menor visibilidad tendrá a la hora de detectar anomalías puntuales (que son las que nos interesan). Justo lo contrario ocurrirá si las gráficas son muy abruptas; la capacidad de predicción será menor ya que los datos variarán mucho en el tiempo y al algoritmo le costará inferir un resultado real.
Probad y comprobad vosotros mismos qué configuración es la que mejor se adecúa a los datos que tenéis. En este caso, y haciendo zoom en un periodo de 5 días, tendríamos esta gráfica:

Como podéis comprobar se observan 3 gráficas diferentes. La azul son los logins fallidos que ha habido (valor real). La línea amarilla es la predicción realiza por Splunk. La banda amarilla clara pertenece al intervalo de confianza que ha generado Splunk. La roja es la diferencia de los logins realizados menos los logins predichos. Nosotros tomaremos como válido o normal cualquier valor real que se encuentre dentro de la banda amarilla (banda de confianza) y tomaremos como anomalía todo valor que se salga de la misma. Ahora bien, ¿será capaz esta configuración de detectar como anómalo los picos que se mostraron anteriormente?
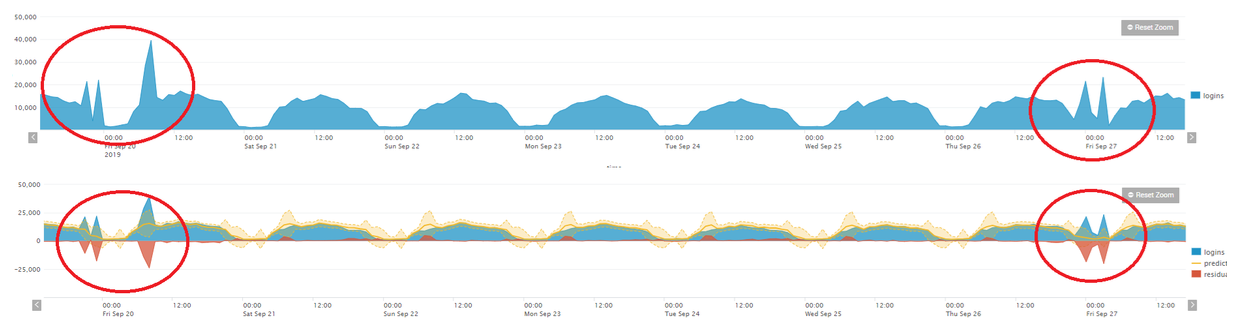
Como se puede observare en la gráfica de abajo, cuando se detecta un incremento del número de logins fallido que el modelo no espera, este no es capaz de predecirlo. Es ahí cuando nosotros deberemos generar una alerta indicando que hemos visto un comportamiento anómalo y debe ser investigado. Para realizar esto, debemos dejar un periodo de tiempo amplio en aras de poder ‘entrenar’ a nuestro modelo de datos. Una vez hecho esto solo nos interesa mostrar aquellos datos que se hayan detectado como anómalos en la última hora (en este caso se corre la alerta una vez cada hora). Para ello basta con añadir la sentencia:
|where _time> now()-3600 AND logins > upper95
Esto solo mostrará los resultados de la última hora cuyo número de logins sea mayor que los esperados en la variable upper95. El resultado es algo similar a:
| tstats count FROM datamodel=Authentication summariesonly=true where Authentication.action="failure" by Authentication.action, _time span=1
| timechart values(count) AS logins span=1
| predict logins as prediction algorithm=LLP future_timespan=30 holdback=110
| where prediction!="" AND logins!=""
| eval residual = prediction - login
| where _time > now()-3600 AND logins > upper95
Conclusiones
Como se puede observar, aplicar sistemas de detección de anomalías hoy en día es bastante sencillo con los sistemas de correlación modernos. Nos permite detectar, con relativa sencillez, comportamientos anómalos que puede derivar en una investigación. Además, se adaptan mejor a los datos y no son deterministas. Esto ayuda a no tener que andar realizando revisiones constantes de umbrales de otro tipo de alertas. Este tipo de detecciones puede ser aplicada a cualquier patrón que sea repetitivo como por ejemplo volumen del tráfico de red, horario de login de los usuarios en el trabajo, etc.