La gestión centralizada del registro de eventos desempeña un papel crucial en la supervisión de ciberseguridad y análisis forense de redes, ya que permite reunir eventos de miles de nodos (servidores, dispositivos de red, sensores IPS, etc.) en unos pocos servidores dedicados donde se realiza el análisis central. El análisis puede ser un proceso en tiempo real, donde los incidentes de seguridad se detectan a partir de eventos entrantes a través de la correlación de eventos y otras técnicas avanzadas de monitorización, también puede ser una actividad forense offline, donde se investigan eventos pasados para estudiar incidentes de seguridad que ya han ocurrido. Sin la recopilación de eventos en las ubicaciónes centrales, las actividades de supervisión y análisis forense tendrían que llevarse a cabo en nodos de red individuales, lo cual lleva mucho tiempo y evita la resolución oportuna de incidentes de seguridad.
Por ejemplo, si un incidente de seguridad involucra cientos de nodos de red, los registros de eventos para todos los nodos tendrían que analizarse por separado. Además, el atacante puede borrar eventos del registro de eventos local para eliminar cualquier rastro de sus actividades maliciosas. Si se registran todos los eventos, tanto localmente como en un servidor de recopilación de registros central, este último siempre tendrá una copia del registro de eventos original, lo que facilita la investigación forense incluso si se pierde el registro original.
Por las razones anteriores, se han creado varias soluciones comerciales y de código abierto para la recopilación de eventos y el análisis centralizado. Algunas de estas soluciones están diseñadas solo para la gestión de registros, mientras que otras son marcos completos de SIEM (Información de seguridad y Gestión de eventos). La imagen proporciona una descripción general de los componentes esenciales de un marco de gestión de registro de eventos:
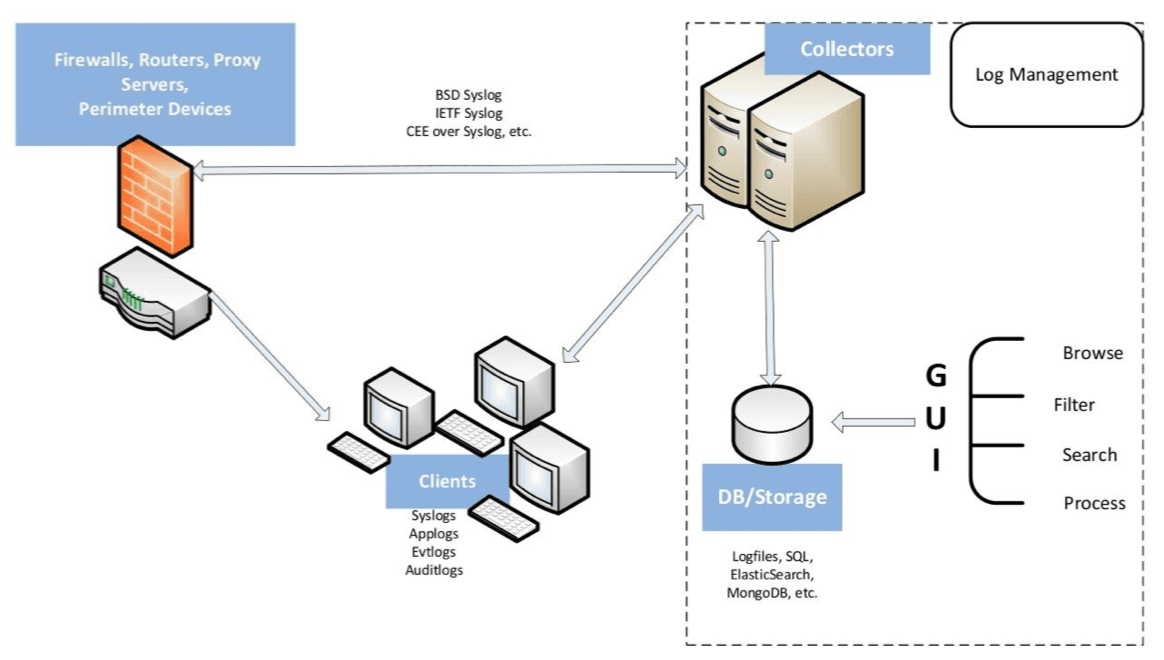
Como se muestra, los nodos del sistema de TI están utilizando protocolos como IETF syslog para enviar eventos a los servicios del recopilador en el servidor de registro central. Los servicios de recopilación utilizan diversas técnicas para filtrar y normalizar eventos y almacenar eventos preprocesados en algunos medios de almacenamiento (por ejemplo, una base de datos o un archivo plano). El personal de ciberseguridad pueden acceder a los datos almacenados a través de una GUI para realizar búsquedas, crear informes y otras tareas analíticas.
Si bien las soluciones de administración de registros comerciales son revisadas y comparadas regularmente por organizaciones independientes (por ejemplo, los informes del Cuadrante Mágico de Gartner para soluciones SIEM):
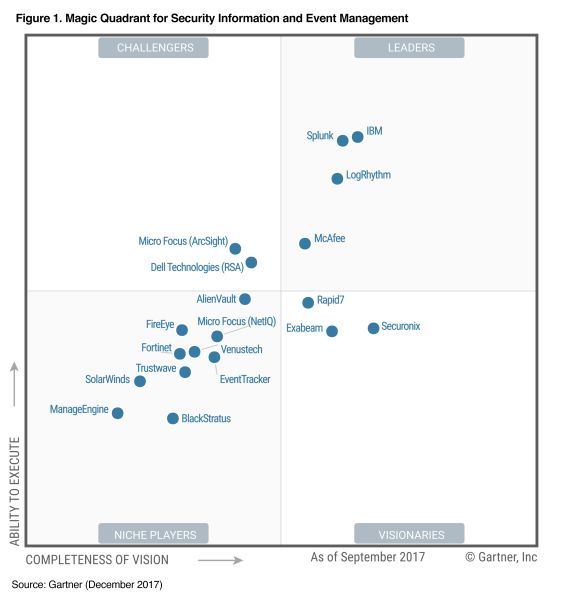
Estas comparaciones a menudo son difíciles de encontrar para herramientas de código abierto, especialmente para soluciones creadas recientemente. Sin embargo, muchas instituciones están utilizando herramientas de código abierto para monitorizar y hacer análisis forense, ya que permiten la implementación de marcos de detección y análisis de incidentes de una manera rentable. Además, las soluciones de código abierto recientemente presentadas han iniciado una nueva tendencia arquitectónica, donde el sistema de gestión de registros consta de módulos independientes y reemplazables que interactúan a través de interfaces y protocolos bien definidos. Por el contrario, la mayoría de los sistemas comerciales son esencialmente soluciones monolíticas donde los componentes individuales (como la GUI o el servicio de recopilador de eventos) no se pueden cambiar para un componente de otro proveedor.
En el post nos centraremos en las soluciones de código abierto para la gestión de registros recientes en este campo, que cubren las nuevas tecnologías y soluciones que han aparecido durante los últimos 2 o 3 años. En primer lugar, proporcionaremos una descripción general de los protocolos de recopilación de logs de uso común y las técnicas de almacenamiento de registros. Luego, pasaremos a una descripción detallada de los servidores de recopilación de eventos avanzados y los sistemas de administración de registros gráficos. La primera contribución de este documento es una comparación analítica de las herramientas presentadas, la segunda contribución es una evaluación comparativa detallada del desempeño de las herramientas. Para este propósito, realizamos una serie de experimentos para evaluar el consumo de recursos y la velocidad de procesamiento de eventos bajo una carga pesada. Hasta donde sabemos, tales evaluaciones de desempeño no se han llevado a cabo recientemente para soluciones de gestión de registro de código abierto de última generación.
Protocolos de recopilación de eventos en logs
BSD syslog protocol
Hasta la década de 1980, el registro de eventos se lograba principalmente escribiendo eventos en un archivo que residía en un sistema de archivos local, o en algún otro medio de almacenamiento local de eventos (por ejemplo, un buffer de anillo basado en la memoria). En la década de 1980, Eric Allman propuso el protocolo BSD syslog para la recopilación de registros de eventos, que se utilizó inicialmente en el sistema de envío de correos de sendmail, pero luego gradualmente fue ampliamente aceptado por la mayoría de los proveedores. De acuerdo con el protocolo syslog de BSD, los mensajes de registro se envían a través de la red como datagramas UDP, con cada mensaje encapsulado en un paquete UDP separado. Cada mensaje tiene cierta facilidad y gravedad, donde la instalación indica el tipo de remitente. El protocolo BSD define 24 valores de facilidad y 8 valores de severidad que van de 0 a 23 y de 0 a 7 respectivamente. Por ejemplo, el valor de facilidad 0 significa un kernel del sistema operativo, 2 un sistema de correo y 3 un daemon del sistema, mientras que el valor de gravedad 7 significa un mensaje de depuración, 4 un mensaje de advertencia y 0 un mensaje de emergencia. Por razones de conveniencia, a menudo se usan acrónimos textuales en lugar de números, p. el correo denota la instalación 2 y la advertencia denota la gravedad 4.
Según BSD syslog, la carga útil del paquete UDP que transporta el mensaje debe tener el formato <Priority> Timestamp Hostname MSG, donde Priority se define como una cadena de caracteres de un número (8 * facility_value ) + severity_value. Por ejemplo, el siguiente mensaje representa una advertencia: "ids 1299 : escaneo de puerto desde 192.168.1.102" para la instalación daemon que se emitió el 17 de noviembre a las 12:33:59 por el nodo de red myhost2:
<28>Nov 17 12:33:59 myhost2 ids[1299]: port scan from 192.168.1.10
Por convención, los alfanuméricos que inician el campo MSG se consideran como el subcampo Etiqueta que representa el nombre del programa emisor ("ids" en el ejemplo anterior), mientras que el resto del campo MSG se considera como el subcampo Contenido ("1299: escaneo de puertos de 192.168.1.102 "en el ejemplo anterior). El subcampo Etiqueta a menudo va seguido de un número entre corchetes que representa el ID del proceso del programa de envío (1299 en el ejemplo anterior). Tenga en cuenta que algunos servidores syslog consideran el ID del proceso con corchetes y los dos puntos como parte del campo Etiqueta.
Por un lado, dado que BSD syslog está basado en UDP, es un protocolo liviano y eficiente que consume muy poco ancho de banda de red y recursos del sistema. Por otro lado, el protocolo tiene una serie de inconvenientes que se resumen a continuación:
- No admite la transmisión confiable de mensajes a través de TCP.
- No admite cifrado y autenticación.
- Las marcas de tiempo no son lo suficientemente específicas, ya que carecen del número de año, la información de la zona horaria y las fracciones de segundo.
- Aparte del nombre del programa emisor y su ID de proceso, el campo MSG no tiene estructura.
Para abordar el primer problema, se propuso un "sabor" TCP del protocolo syslog BSD durante la década anterior, donde se envía una secuencia de mensajes en formato syslog BSD a través de una conexión TCP, con un carácter de nueva línea (ASCII 10) que actúa como separador entre mensajes. Este tipo de protocolo también permite el uso de otras utilidades (por ejemplo, stunnel) para configurar túneles seguros para el registro y, por lo tanto, para abordar el segundo problema.
IETF syslog protoco
En 2009, se propuso el protocolo Syslog de IETF que aborda los inconvenientes de BSD syslog. El syslog de IETF admite la transmisión segura de mensajes a través de TLS, pero también la transmisión no encriptada a través de UDP. Además, utiliza un nuevo formato de mensaje con marcas de tiempo RFC3339 más detalladas y bloques de datos estructurados. El siguiente ejemplo representa el mensaje de muestra anterior en el nuevo formato:
<28>1 2012-11-17T12:33:59.223+02:00 myhost2 ids 1299 - [timeQuality tzKnown="1" isSynced="1"][origin ip="10.1.1.2"] port scan from 192.168.1.102
La especificación de prioridad <28> es seguida inmediatamente por el número de versión del protocolo (actualmente establecido en 1). Además, el emisor está pasando dos bloques de datos estructurados timeQuality tzKnown = "1" isSynced = "1" y origin ip = "10.1.1.2" al remitente, y el primero indica que el reloj del remitente está sincronizado a una fuente de tiempo externa confiable, y el segundo que indica la dirección IP del remitente.
CEE syslog format
Otro esfuerzo actualmente en curso para introducir estructura para registrar mensajes es la iniciativa de Expresión de Eventos Comunes (CEE). CEE ha propuesto formatos JSON y XML para eventos, al tiempo que sugiere el uso de los protocolos syslog BSD e IETF para transportar eventos con formato JSON. A continuación, se muestra un evento de ejemplo en formato JSON que se ha encapsulado en un mensaje de syslog de BSD:
<28>Nov 17 12:33:59 myhost2 ids[1299]: @cee:{"pname":"ids","pid":1299,"msg":"port scan from 192.168.1.102","action":"portscan","dst":"192.168.1.102"}
Pasar tal estructura de pares de palabras clave-valor del remitente al receptor facilitará el análisis del mensaje en el lado del receptor. Además, el formato JSON es compatible con los protocolos syslog BSD e IETF, ya que este formato se usa dentro del campo MSG, que no tiene una estructura predefinida.
Otros protocolos de registro de logs
Además de los protocolos de registro de eventos antes mencionados, se podrían emplear otros protocolos para la recopilación de eventos. A continuación, discutiremos brevemente algunas alternativas a BSD e IETF syslog. El protocolo SNMP es un protocolo bien establecido de monitorización y administración basado en UDP que se introdujo en la década de 1980. Aunque el enfoque principal de SNMP radica en la gestión de fallas y rendimiento de redes grandes, la información relacionada con la seguridad a veces se transmite con mensajes SNMP (mensajes de trampa o de notificación). En el dominio de código abierto, hay herramientas para recibir notificaciones de SNMP y almacenarlas en archivos, como proyectos Net-SNMP y SNMPTT . También hay algunos protocolos específicos de aplicaciones para la transmisión de eventos, por ejemplo, el protocolo rsyslog RELP para la transmisión confiable de mensajes, el protocolo GELF (Graylog Extended Log Format) para el registro estructurado, el protocolo Sourcefire Estreamer para transmitir alarmas IDS con paquetes de carga, etc.
Técnicas de almacenamiento de registros de eventos
Almacenamiento de registros en archivos
Cuando los registros se recopilan en los servidores centrales, se deben escribir en un almacenamiento permanente, para que el análisis fuera de línea de los eventos pasados se pueda llevar a cabo más adelante. La forma más común de almacenar registros es escribir los mensajes de registro entrantes en archivos planos que residen en el disco del servidor central. Con este enfoque, los archivos de registro separados generalmente se crean registrando el host, la aplicación, el tipo de mensaje o por algún otro criterio, y los archivos de registro a menudo se organizan en alguna estructura de directorio, de modo que se pueda ubicar rápidamente un archivo de registro relevante. Mientras que almacenar mensajes en archivos planos consume poco tiempo de CPU y permite que el servidor log reciba grandes volúmenes de eventos por segundo, buscar eventos relevantes desde archivos planos puede consumir mucho tiempo y recursos. En las redes informáticas actuales, se pueden generar muchos gigabytes de datos de registro cada día, e incluso si estos datos se dividen entre muchos archivos, los archivos individuales aún pueden ser bastante grandes. Como resultado, está más allá de las capacidades humanas revisar esos registros de forma manual, y los eventos interesantes generalmente se pueden identificar solo con búsquedas de expresiones regulares. Por ejemplo, a menudo los administradores del sistema utilizan herramientas online de comandos como egrep o pcregrep para buscar eventos con expresiones regulares. Desafortunadamente, el uso de un lenguaje de expresiones regulares para cada búsqueda individual consume mucha CPU y lleva tiempo.
Almacenamiento de registros en bases de datos SQL
Por las razones indicadas anteriormente, la inserción de mensajes de registro en bases de datos SQL ha sido otro enfoque común para almacenar datos de registro. Sin embargo, insertar un mensaje en una base de datos es considerablemente más costoso que escribirlo en un archivo plano.
- En primer lugar, el mensaje debe analizarse y dividirse en campos que corresponden a las columnas de la tabla de la base de datos que contiene los datos de registro. Si el texto del mensaje de registro no está estructurado, dicho análisis se puede hacer a menudo solo con expresiones regulares.
- En segundo lugar, la operación de inserción de la base de datos consume mucho más tiempo de CPU que una operación de escritura en un archivo, lo que se hace con una sola llamada al sistema.
Sin embargo, el gasto adicional de almacenar datos de registro en una base de datos permite una búsqueda mucho más flexible y eficiente. Además, los nuevos estándares de registro que soportan mensajes de registro estructurados (por ejemplo, el registro sistémico IETF) reducen el costo del análisis sintáctico, ya que el mensaje ya contiene campos claramente definidos. Por lo tanto, muchas soluciones SIEM comerciales están utilizando una base de datos SQL como almacenamiento de eventos primarios.
El uso de bases de datos SQL presenta un problema: cada tabla de base de datos contiene un número fijo de columnas, donde cada columna representa un cierto campo de mensaje de un tipo fijo (por ejemplo, entero o cadena). Como consecuencia, los campos de un mensaje de registro deben cumplir con la estructura de una tabla de base de datos que contiene los datos de registro. Para abordar este requisito, los campos de todos los mensajes recopilados deben conocerse con antelación, de modo que se pueda definir el esquema de base de datos apropiado. Por ejemplo, supongamos que el servidor de registro central se utiliza para recopilar alarmas de Snort IDS, con el siguiente ejemplo que representa una alarma entrante en formato de syslog de BSD:
<33>Nov 25 17:37:12 ids4 snort[776]: [1:1156:13] WEB-MISC apache directory disclosure attempt [Classification: Attempted Denial of Service] [Priority: 2]: {TCP} 10.2.1.99:41337 -> 192.168.1.1:80
Para almacenar dichas alarmas, se puede configurar una tabla de base de datos de manera sencilla con las siguientes columnas: Marca de tiempo, Nombre de host, SignatureID, SignatureRevision, AlarmText, Clasificación, Prioridad, Transporte, SourceIP, SourcePort, DestinationIP y DestinationPort. Para la alarma de ejemplo anterior, las columnas se llenarán de la siguiente manera:
Timestamp="Nov 25 17:37:12"; Hostname="ids4"; SignatureID="1:1156"; SignatureRevision="13"; AlarmText="WEB-MISC apache directory disclosure attempt"; Classification="Attempted Denial of Service"; Priority="2"; Transport="TCP"; SourceIP="10.2.1.99"; SourcePort="41337"; DestinationIP="192.168.1.1"; DestinationPort="80"
Almacenamiento de registros en bases de datos orientadas a documentos
Desafortunadamente, si los registros se reciben de una amplia variedad de fuentes, el entorno cambia constantemente y es probable que aparezcan mensajes de registro en formatos no vistos anteriormente. El uso de bases de datos SQL implica una gran cantidad de trabajo administrativo general, ya que para cada formato de mensaje nuevo se debe configurar un nuevo esquema de análisis. Además, si los mensajes entrantes tienen una gran variedad de campos, es engorroso almacenarlos en la misma tabla de base de datos, ya que la tabla debe tener columnas para todos los campos de mensajes relevantes. Aunque algunas soluciones SIEM definen tablas de bases de datos con un gran número de columnas y dejan varias de ellas para almacenar datos de registro personalizados, este enfoque es, sin embargo, engorroso y no escalable.
Para abordar este problema, las bases de datos orientadas a documentos han surgido como soluciones alternativas de almacenamiento de registros durante los últimos 1-2 años. Las bases de datos orientadas a documentos son una categoría importante de bases de datos no SQL que no emplean tablas con columnas predefinidas para almacenar los datos. Aunque las implementaciones de las bases de datos orientadas a documentos varían, se pueden ver como una colección de documentos, donde cada documento suele ser un registro de pares nombre-valor de campo. El motor de base de datos permite buscar documentos almacenados según diversos criterios, por ejemplo recuperar documentos con algunos campos que tienen un cierto valor. Dependiendo de la base de datos, varios formatos como JSON y XML son compatibles con los documentos insertados. Es importante tener en cuenta que cada documento insertado puede tener un conjunto único de nombres de campo que no es necesario conocer con anticipación. Por ejemplo, los siguientes mensajes de registro en formato JSON se pueden almacenar en la misma base de datos:
{"timestamp":"Nov 25 17:37:12","host":"ids4","program":"snort","processid":776,"sigid":"1:1156", "revision":13,"alarmtext":"WEB-MISC apache directory disclosure attempt","classification": "Attempted Denial of Service","priority":2,"transport":"TCP","sourceip":"10.2.1.99","sourceport": 41337,"destinationip": "192.168.1.1","destinationport":80}
{"timestamp":"Nov 25 17:38:49","host":"myhost","program":"sshd","processid":1022,"messagetext": "Failed password for risto from 10.1.1.1 port 32991 ssh2","username":"risto","sourceip":"10.1.1.1", "sourceport":32991}
Durante los últimos 1-2 años, Elasticsearch se ha convertido en uno de los motores de base de datos orientados a documentos más utilizados para almacenar datos de registro.
![]()
Elasticsearch está escrito en Java y se utiliza como backend en varios paquetes populares de administración de registros recientemente creados como Graylog2, Logstash y Kibana. Desde servidores syslog bien establecidos, también es compatible con rsyslog. Elasticsearch acepta nuevos documentos en formato JSON a través de una interfaz HTTP simple, insertando el documento entrante en un índice de base de datos dado y haciendo que el documento pueda buscarse para futuras consultas. Si el índice no existe, se creará automáticamente. Por ejemplo, la siguiente línea de comandos simple de UNIX utiliza la utilidad curl para insertar manualmente el ejemplo anterior de mensaje de registro con formato JSON en la base de datos Elasticsearch local (de forma predeterminada, el servidor acepta nuevos documentos en el puerto TCP 9200). El mensaje de registro se inserta en el registro de sistema del índice, con el tipo de mensaje configurado en ssh y el ID de mensaje establecido en 1:
curl -XPUT 'http://localhost:9200/syslog/ssh/1' -d '{"timestamp":"Nov 25 17:38:49","host":"myhost", "program":"sshd","processid":1022,"messagetext": "Failed password for risto from 10.1.1.1 port 32991 ssh2","username":"risto","sourceip":"10.1.1.1", "sourceport":32991}'
El soporte para la distribución está integrado en el núcleo de Elasticsearch. Varias instancias de motores Elasticsearch se pueden unir fácilmente en un único clúster, mientras que el descubrimiento automático de nuevos nodos de clúster se implementa a través de la multidifusión de red. Además, cada índice de base de datos se puede dividir en los denominados fragmentos, que pueden ubicarse en diferentes miembros del clúster. Cada índice puede tener una o más réplicas para implementar un clúster tolerante a errores. De forma predeterminada, cada índice se divide en 5 fragmentos y tiene 1 réplica (es decir, 5 fragmentos de réplica). Con la configuración predeterminada, cada índice se puede distribuir a través del clúster de hasta 10 nodos. Muchas tareas administrativas se pueden llevar a cabo a través de la interfaz web de una manera sencilla, como el ejemplo de inserción de mensaje anterior. Por ejemplo, la siguiente línea de comando crea un nuevo índice syslog2 con 10 fragmentos y ninguna réplica:
curl -XPUT 'http://localhost:9200/syslog2/' -d '{ "settings" : { "index" : { "number_of_shards":10, "number_of_replicas":0 } } }
La siguiente línea de comando cambia la cantidad de réplicas de 0 a 1 para el índice syslog2:
curl -XPUT 'http://localhost:9200/syslog2/_settings' -d '{ "number_of_replicas":1 }'
Servidores Syslog
En el apartado anterior, revisamos los protocolos de recopilación de registros y las técnicas de almacenamiento de registros. En esta, veremos los principales servidores syslog de código abierto que implementan todos los tipos del protocolo syslog, y pueden almacenar registros de la forma descrita. Los tres servidores syslog más utilizados en el dominio de código abierto son rsyslog, syslog-ng y nxlog.
Rsyslog, syslog-ng and nxlog
Rsyslog, syslog-ng y nxlog se diseñaron para superar las deficiencias de las implementaciones tradicionales de servidor syslogd de UNIX, que normalmente solo admiten el protocolo syslog BSD basado en UDP, y son capaces de unir y procesar mensajes por instalación y gravedad. Por ejemplo, la siguiente declaración de UNIX syslogd coincidirá con todos los mensajes para el daemon y el recurso del usuario con la advertencia de grave o superior, y almacenará dichos mensajes en el archivo /var/log/warn.log:
daemon.warning;user.warning /var/log/warn.log
Rsyslog, syslog-ng y nxlog son compatibles no solo con la coincidencia simple de mensajes, sino también con el reconocimiento avanzado de mensajes con expresiones regulares, conversión de mensajes de un formato a otro, comunicaciones autenticadas y encriptadas sobre el protocolo syslog IETF, etc. Para syslog-ng y nxlog.
Existen dos versiones separadas: además de una versión de código abierto, también hay una edición comercial con funcionalidad extendida. Rsyslog y syslog-ng se ejecutan en plataformas UNIX, mientras que nxlog también puede funcionar en Windows.
La configuración de todos los servidores se almacena en uno o más archivos de configuración de texto. Syslog-ng utiliza un lenguaje de configuración altamente flexible y legible que no es compatible con UNIX syslogd. Las fuentes de mensajes, las condiciones de coincidencia y los destinos se definen con bloques con nombre, siendo cada definición reutilizable en otras partes de la configuración. Syslog-ng también está muy bien documentado, presentando un detallado manual del administrador que consta de cientos de páginas. Esto hace que sea fácil crear configuraciones bastante complejas, incluso para usuarios inexpertos.
Rsyslog usa un lenguaje de configuración bastante diferente que admite construcciones syslogd de UNIX. Esto permite una migración fácil de las configuraciones antiguas de syslogd a la plataforma rsyslog. Además de las construcciones syslogd de UNIX, hay muchas características adicionales en el lenguaje de configuración rsyslog. Lamentablemente, con el tiempo, varias sintaxis diferentes se han incluido en el lenguaje que ha introducido incoherencias. Además, rsyslog carece de un completo manual de administrador, y en el sitio web de rsyslog se proporciona un conjunto limitado de ejemplos de configuración que no cubren todos los escenarios de configuración. Afortunadamente, se puede encontrar mucha información de otros sitios web, y rsyslog tiene una lista de correo activa. Funcionalmente, rsyslog admite varias funciones muy útiles que no están presentes en las versiones de código abierto, syslog-ng y nxlog. En primer lugar, es posible configurar el almacenamiento de mensajes temporales en el disco local para los mensajes de registro que no se enviaron correctamente a través de la red. El almacenamiento en búfer se activa cuando se interrumpe la conexión con un par remoto, y cuando el par vuelve a estar disponible, todos los mensajes almacenados en el búfer se retransmiten. En segundo lugar, la última versión estable de rsyslog tiene soporte para la base de datos Elasticsearch.
Nxlog usa el lenguaje de configuración de estilo Apache. Al igual que con syslog-ng, las fuentes de mensajes, los destinos y otras entidades se definen con bloques con nombre que les permite reutilizarse fácilmente. Además, nxlog tiene un sólido manual de usuario. Las ventajas de nxlog sobre otros servidores syslog incluyen soporte nativo para la plataforma Windows y el registro de eventos de Windows. Además, nxlog puede aceptar eventos de entrada de varias fuentes que no son compatibles directamente con otros servidores, incluidas bases de datos SQL y archivos de texto en formatos personalizados. Finalmente, nxlog puede generar mensajes de salida en formato GELF, lo que facilita su integración con la solución de visualización de registro Graylog2.
Para ilustrar las diferencias entre los lenguajes de configuración de syslog-ng, rsyslog y nxlog, mostramos sentencias de configuración en tres idiomas para el mismo escenario de procesamiento de registros:
Configuración para syslog-ng @version:3.3
source netmsg { udp(port(514)); }; filter ntpmsg { program('^ntp') and level(warning..emerg); }; destination ntplog { file("/var/log/ntp-faults.log"); }; log { source(netmsg); filter(ntpmsg); destination(ntplog); }; ##### configuration for rsyslog $ModLoad imudp $UDPServerRun 514 if re_match($programname, '^ntp') and $syslogseverity <= 4 then { action(type="omfile" file="/var/log/ntp-faults.log")
Configuración para nxlog
<Input netmsg> Module im_udp Host Port Exec </Input> 0.0.0.0 514 parse_syslog_bsd(); <Output ntplog> Module om_file File "/var/log/ntp-faults.log" Exec if $SourceName !~ /^ntp/ or $SyslogSeverityValue > 4 drop(); </Output> <Route ntpfaults> Path netmsg => ntplog </Route
Primero, las configuraciones anteriores dicen a los servidores syslog que acepten los mensajes syslog de BSD desde el puerto UDP 514 (en el caso de syslog-ng y nxlog, el nombre netmsg se asigna a este origen de mensaje). Luego, la condición de filtrado del mensaje se define para detectar mensajes con el campo Etiqueta que coincide con la expresión regular ^ ntp (en otras palabras, el nombre del programa emisor comienza con la cadena "ntp") y con la gravedad del mensaje entre advertencia ( código 4) y emerg (código 0). Ten en cuenta que para nxlog, el filtro inverso se usa realmente para descartar mensajes irrelevantes. Finalmente, el archivo /var/log/ntp-faults.log se utiliza como destino para almacenar mensajes que han pasado el filtro (en el caso de syslog-ng y nxlog, el nombre ntplog se asigna a este destino).
Experimentos para evaluar el rendimiento de rsyslog, syslog-ng y nxlog
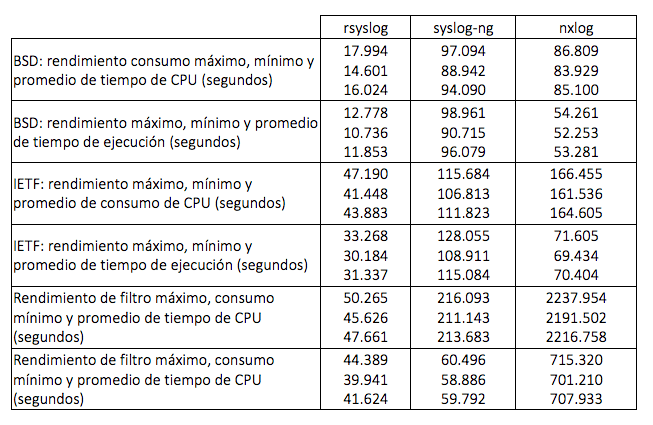
Para evaluar si cada servidor es adecuado para el rol de un servidor syslog central, veremos una serie de experimentos para evaluar su rendimiento. Durante los experimentos, utilizamos tres puntos de referencia para probar el estrés de los servidores, y medimos el consumo de tiempo de CPU y el tiempo de ejecución general de cada servidor durante cada ejecución de prueba.
- BSD-Throughput: Configura 1 cliente que envía 10,000,000 mensajes de syslog BSD de texto plano al servidor syslog a través de TCP. Los mensajes se escriben en un archivo de registro sin ningún tipo de filtrado.
- IETF-Throughput: Configura 1 cliente que envía 10,000,000 mensajes syslog cifrados IETF al servidor syslog a través de TCP. Los mensajes se escriben en un archivo de registro sin ningún tipo de filtrado.
- Filter-Throughput: Configura 5 clientes, cada uno enviando 2.000.000 mensajes de syslog BSD de texto plano al servidor syslog a través de TCP. Los mensajes son idénticos a los mensajes del benchmark BSD-Throughput que permite hacer comparaciones de rendimiento entre dos benchmarks. El servidor está configurado para procesar datos de registro entrantes con 5 filtros y para escribir mensajes en 5 archivos de registro. Todos los filtros incluyen condiciones de coincidencia de expresiones regulares para el texto del mensaje (campo de contenido) y/o el nombre del programa (campo de etiqueta), y algunos filtros también tienen condiciones de coincidencia adicionales para facilidad de mensajes y la gravedad.
Ten en cuenta que el multi-threading está integrado en el núcleo de rsyslog y nxlog, mientras que para syslog-ng este modo debe habilitarse manualmente. Durante las pruebas se descubrió que para BSD-Throughput y IETF-Throughput syslog-ng, el rendimiento disminuía en el modo multi-threading. De acuerdo con el manual de syslog-ng, este modo produce beneficios de rendimiento en presencia de muchos clientes, filtros y destinos de mensajes, mientras que para el escenario de "un cliente único, destino único", podría estar involucrado el gasto de cómputo. Por lo tanto, se ejecutó syslog-ng en un modo de subproceso único predeterminado para BSD-Throughput y IETF-Throughput tests. Además, se descubrió que la versión probada de nxlog no era capaz de manejar los mensajes syslog de IETF según lo requerido por RFC5425: en una secuencia de mensajes entrantes, solo se reconocía correctamente el primer marco syslog. Además, la versión probada no pudo reconocer 'Z' como la especificación de zona horaria en la marca de tiempo RFC3339, pero la consideró incorrectamente como el nombre del host de envío. Por esta razón, se tuvo que modificar el benchmark IETF-Throughput para nxlog, de modo que en lugar de las tramas RFC5425 apropiadas, se enviara una secuencia de mensajes IETF separados por nueva línea a nxlog a través de la conexión TLS (ten en cuenta que este modo de transmisión de datos no oficial es compatible con todos los servidores probados como una extensión de los modos definidos por RFC). Las pruebas se llevaron a cabo en un nodo de Fedora Linux con 8 GB de memoria y un procesador Intel Core i5 650. Repitiendo cada prueba 10 veces, presentando los resultados en la Tabla.
Los resultados revelanron varios aspectos interesantes del rendimiento del servidor. En primer lugar, el rendimiento de rsyslog es superior a otros servidores, tanto en términos de rendimiento de mensajes sin formato de un solo cliente como de eficiencia del filtrado de mensajes para múltiples clientes. Además, rsyslog puede compartir su carga de trabajo entre varios núcleos de CPU con multi-threading, y por lo tanto los tiempos de ejecución son menores que los tiempos totales de CPU consumidos. El Multi-threading se usa de manera muy eficiente mediante nxlog, lo que resulta en tiempos de ejecución 1.5-3 veces más bajos que el tiempo de CPU utilizado. Desafortunadamente, el rendimiento de los filtros nxlog es muy pobre e incluso la introducción de algunos filtros de expresiones regulares disminuye significativamente el rendimiento: en comparación con la prueba BSD-Throughput, el consumo promedio de tiempo de la CPU aumentó unas 26 veces. Por el contrario, el consumo de tiempo de la CPU para syslog-ng aumentó solo 2.27 veces, mientras que el tiempo promedio de ejecución disminuyó casi a la mitad debido al modo de multi-threading habilitado manualmente.
Aplicaciones de visualización y preprocesamiento de logs
Los servidores syslog analizados anteriormente pueden recibir grandes volúmenes de datos de registro a través de la red y almacenar estos datos en archivos y bases de datos. Si bien el uso de bases de datos para almacenar los mensajes de registro facilita la búsqueda rápida con un lenguaje de consulta flexible, sería tedioso y tomaría mucho tiempo al usuario escribir consultas separadas para cada búsqueda, informe u otra tarea analítica. Además, el resultado de las consultas de la base de datos es textual y el usuario debería usar una herramienta separada, o incluso un lenguaje de programación, para visualizar esta salida. Para solucionar este problema, se han desarrollado varias aplicaciones de visualización de registro de código abierto durante los últimos 1-2 años, que usan Elasticsearch como su motor de base de datos principal. En esta sección, revisaremos y realizaremos experimentos de evaluación de rendimiento para Logstash, Graylog2 y Kibana.
Logstash
![]()
Logstash es una utilidad basada en Java donde una interfaz gráfica de usuario y el motor Elasticsearch incorporado se encapsulan en un archivo jar independiente. Esto facilita la instalación de Logstash ya que el usuario no tiene que descargar e instalar todos los componentes del producto por separado. Una ventaja de Logstash es su compatibilidad con muchos tipos de entrada diferentes, a través de más de 20 complementos de entrada. Actualmente, hay complementos de entrada para aceptar mensajes syslog no encriptados sobre TCP y UDP, pero también para muchos otros protocolos de mensajería como AMPQ, RELP, GELF, IRC, XMPP, Twitter, etc. Desafortunadamente, no hay soporte para recibir mensajes syslog cifrados de IETF. y para ese propósito, se debe usar un servidor de registro syslog que descifra los mensajes y los reenvía a Logstash. Otra ventaja de Logstash es una serie de diferentes tipos de filtros de mensajes que permiten un reconocimiento flexible, filtrado, análisis y conversión de mensajes. Por ejemplo, es posible convertir mensajes multilínea en mensajes de una sola línea, filtrar los mensajes con expresiones regulares, agregar nuevos campos a los mensajes de consultas externas y realizar muchas otras tareas avanzadas de manipulación de mensajes.
Uno de los tipos de filtro Logstash más utilizados es grok. Si bien la mayoría de las herramientas de administración de registros usan un lenguaje de expresión regular para la concordancia y el análisis de mensajes, los filtros grok emplean muchos patrones predefinidos que representan expresiones regulares para tareas de coincidencia comunes. Por ejemplo, el patrón PROG se define como la expresión regular (?: [\ W ._ /% -] +) y está diseñado para coincidir con el nombre del programa de registro, el patrón POSINT se define como la expresión regular \ b ( ?: [1-9] [0- 9] *) \ b y coincide con un entero positivo, etc. Para analizar cierto campo del mensaje, se usa la sintaxis % {pattern: field . Además, los patrones ya definidos se pueden usar como bloques de construcción para definir nuevos patrones. Utilizando patrones grok predefinidos, una persona que no está familiarizada con el lenguaje de expresiones regulares puede realizar tareas de análisis de eventos de una manera más fácil. Por ejemplo, el siguiente patrón grok coincide con un mensaje syslog de Snort IDS:
snort(?:\[%{POSINT:process_id}\])?: \[%{DATA:signature}:\d+\] %{DATA:alarmtext} \{%{DATA:proto}\} %{IP:srcip}(?::%{POSINT:srcport})? -> %{IP:dstip}(?::%{POSINT:dstport})?
Estableciendo los campos de mensaje process_id, signature, alarmtext, proto, srcip, srcport, dstip y dstport. Además de escribir en la base de datos de Elasticsearch, Logstash admite muchas otras salidas, con más de 40 plugins de salida actualmente disponibles. Entre los resultados, se admiten otros sistemas de supervisión y visualización, incluidos Nagios, Zabbix, Loggly, Graphite y Graylog2.
Para usar la GUI de Logstash, Logstash debe configurarse para insertar eventos en su base de datos incorporada de Elasticsearch. Con la GUI es posible realizar búsquedas básicas desde mensajes de registro en la base de datos integrada. Desafortunadamente, en comparación con otras herramientas de visualización de registro, la GUI de Logstash tiene una funcionalidad bastante limitada. Sin embargo, dado que Logstash tiene poderosas capacidades de filtrado y conversión de eventos, se usa principalmente como un preprocesador de eventos para diferentes sistemas, incluidos otros sistemas de visualización de registros.
Graylog2
Graylog2 es un sistema de administración de registros que consta de un servidor basado en Java y una interfaz web escrita en Ruby-on-Rails. El servidor Graylog2 puede recibir mensajes syslog de BSD sobre UDP y TCP, pero también presenta su propio protocolo GELF que facilita el registro estructurado. Además, Graylog2 puede aceptar mensajes syslog y GELF a través del protocolo de mensajería AMPQ. Desafortunadamente, Graylog2 no puede analizar los mensajes syslog estructurados de IETF y reconocer los pares de nombre de campo definidos ya definidos. Para los mensajes syslog de BSD, Graylog2 puede reconocer los campos estándar de Prioridad, Marca de tiempo, Nombre de host y MSG, pero no puede analizar de forma predeterminada el campo de MSG no estructurado.
El problema de análisis para mensajes no estructurados puede superarse de varias maneras. En primer lugar, el servidor Graylog2 admite el análisis y la reescritura de mensajes a través de las reglas de Drools Expert y las expresiones regulares. En segundo lugar, dado que Logstash admite conversiones avanzadas entre muchos formatos de mensajes con análisis flexible, muchos sitios usan Logstash para recibir mensajes syslog, analizan campos de mensajes relevantes con filtros grok y finalmente envían los mensajes analizados en formato GELF estructurado a Graylog2. Finalmente, dado que el servidor nxlog syslog es compatible con el protocolo GELF, puede utilizarse como interfaz para recibir mensajes syslog encriptados y de texto sin formato y convertirlos en mensajes estructurados GELF.
Para almacenar los mensajes analizados, Graylog2 usa Elasticsearch como su back-end principal (cierta información sobre los mensajes también se almacena en la base de datos MongoDB orientada a documentos, que se utiliza para la creación de gráficos). Desafortunadamente, todos los mensajes de registro se almacenan en un solo índice llamado graylog2, que puede causar problemas de rendimiento ya que muchos mensajes de registro se insertan en el tiempo. Este problema se puede solucionar parcialmente configurando un tiempo de retención de mensajes más corto a través de la interfaz web Graylog2 (de manera predeterminada, los mensajes se mantienen en la base de datos durante 60 días). Sin embargo, sería mucho más eficiente crear un índice separado de Elasticsearch semanal o diariamente (esta última técnica es utilizada por Logstash). Afortunadamente, los desarrolladores de Graylog2 son conscientes de este problema y se supone que se solucionará.
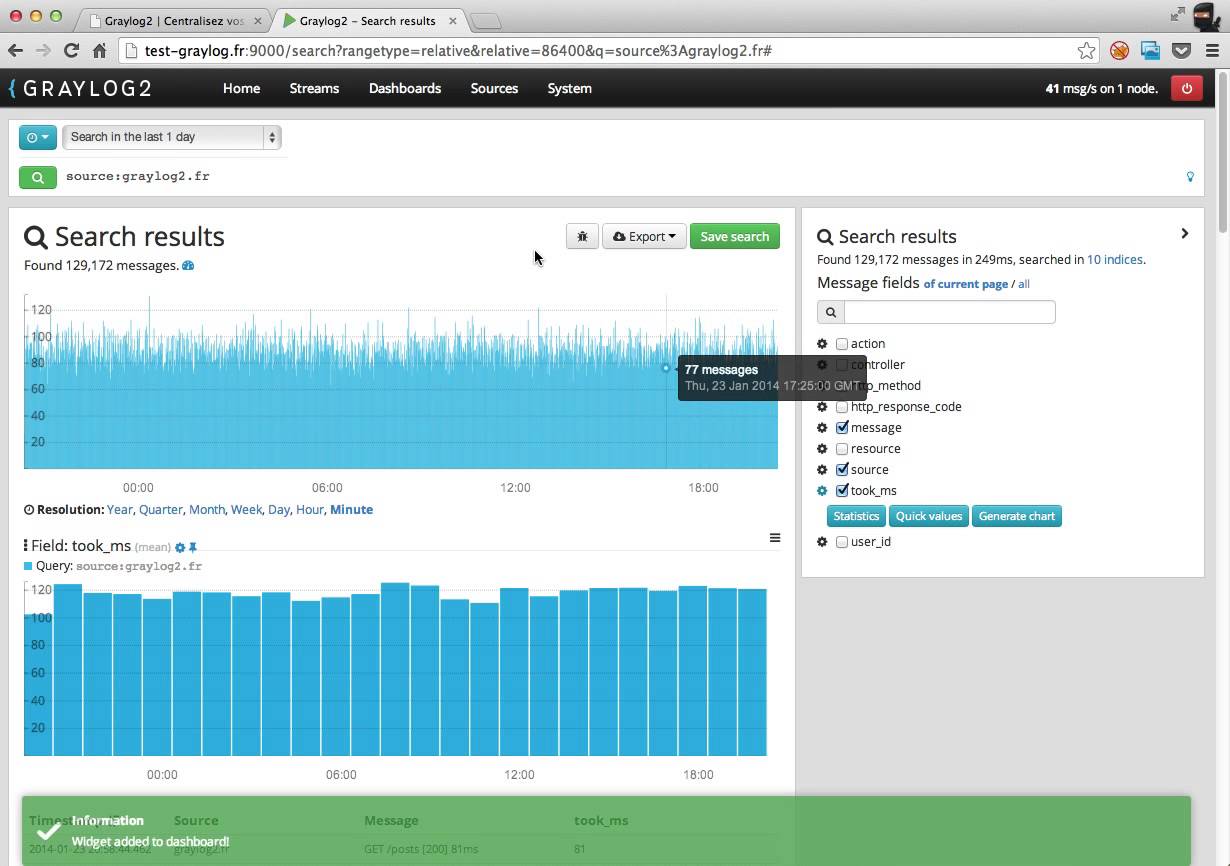
Para visualizar los datos de registro recopilados, Graylog2 proporciona una interfaz web completa y bien escrita. Para acceder a la interfaz, se pueden configurar diferentes cuentas de usuario protegidas por contraseña, con cada usuario teniendo derechos completos o limitados (el resto de la discusión se referirá a la interfaz de usuario con todos los derechos de administrador). La interfaz está dividida en varias partes. La vista de mensaje (Como vemos en la imagen) permite obtener una visión general de los mensajes de registro almacenados, presentando los mensajes en un navegador con los mensajes más recientes en primer lugar. En el navegador, se muestran los campos de fecha y hora, host, gravedad, facilidad y texto del mensaje. Al hacer clic en un mensaje individual, se proporciona una vista detallada del mensaje que contiene todos los nombres de campo con valores. Al hacer clic en cada valor individual se realizará una búsqueda de mensajes con el mismo par fieldname-value, y los mensajes descubiertos se mostrarán en el navegador de mensajes principal. La búsqueda de mensajes también se puede iniciar a través de un botón 'Quickfilter' en la vista de mensajes que permite especificar más de una condición de búsqueda. Para buscar un campo de texto de mensaje, se puede usar la sintaxis de consulta de Apache Lucene. Admite búsquedas de cadenas individuales, coincidencia aproximada de cadenas basada en la distancia de Levenshtein, búsquedas de proximidad (por ejemplo, encuentra dos cadenas que tienen hasta 10 palabras intermedias) y combina condiciones de búsqueda individuales con operadores booleanos.
Además de ver todos los mensajes, el usuario puede configurar flujos que son colecciones de mensajes que satisfacen algunas condiciones de filtrado de mensajes. Las transmisiones se actualizan con mensajes entrantes coincidentes en tiempo real. Los mensajes debajo de cada flujo se pueden ver por separado, y también es posible configurar umbrales y condiciones de alarma para cada flujo (por ejemplo, enviar una alarma a un administrador de seguridad si han aparecido más de 10 mensajes debajo de la transmisión durante 1 minuto). Para definir una condición de filtrado para una secuencia, los valores del campo del mensaje se pueden comparar con valores fijos, pero en el caso de algunos campos, también con expresiones regulares. Al escribir expresiones regulares para el texto de mensaje coincidente, por convención la expresión debe coincidir con el mensaje completo (por ejemplo, para emparejar mensajes que contienen la cadena 'prueba' en el texto del mensaje, la expresión regular debe escribirse no como prueba, sino como). * prueba. * o ^. * prueba. * $). Además de las transmisiones, Graylog2 también contiene un llamado shell de análisis que admite un lenguaje de consulta flexible para encontrar mensajes individuales y para crear varios informes. Desafortunadamente, actualmente todos los informes están basados en texto, aunque en el futuro se podrían agregar soporte para informes gráficos.
Durante el experimentos, se intento establecer el rendimiento de Graylog2 en términos de rendimiento del evento. Esperábamos que el rendimiento de Graylog2 fuera significativamente más lento que el de los servidores syslog probados en la sección anterior. Primero, tanto el servidor Graylog2 como el motor de base de datos Elasticsearch están escritos en Java, mientras que rsyslog, syslog-ng y nxlog están codificados en C. Segundo, el servidor Graylog2 tiene que insertar mensajes de registro en el índice Elasticsearch, lo que requiere mucho más tiempo de CPU que escribir mensajes en archivos planos. Durante las pruebas, se ejecutó Graylog2 en un nodo de Fedora Linux con 8 GB de memoria y un procesador Intel Core i5 650. Se configuró un cliente para Graylog2, que estaba emitiendo una gran cantidad de mensajes syslog BSD sobre TCP. El rendimiento combinado del servidor Graylog2 y el backend Elasticsearch se midió en términos de rendimiento de transmisión de mensajes observado en el lado del cliente. Durante varias pruebas, se pudo alcanzar un rendimiento de 3.500 mensajes por segundo. Esto ilustra que una instancia de servidor Graylog2 no es escalable para entornos muy grandes con muchos miles de hosts de registro y grandes cargas de mensajes. Afortunadamente, los desarrolladores planean agregar soporte en Graylog2 para varias instancias de servidor, lo que debería aumentar sustancialmente su escalabilidad general.
Kibana
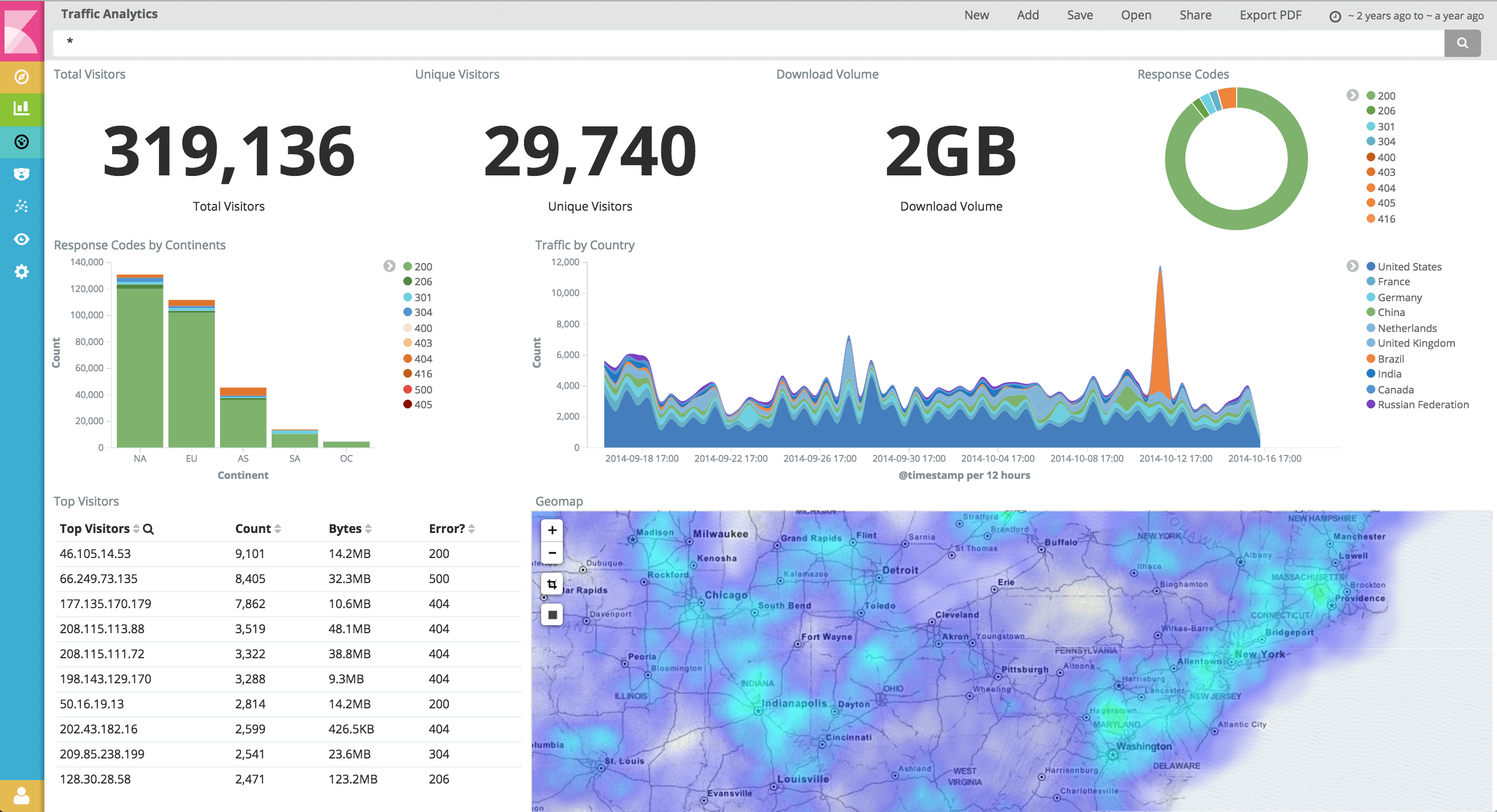
Kibana es otra aplicación para visualizar datos de registro recopilados. A diferencia de Graylog2, Kibana consiste únicamente en una interfaz web basada en Ruby que usa Elasticsearch como back-end, y no hay ningún servidor para recibir mensajes de registro en la red y almacenarlos en una base de datos. Por este motivo, Kibana no puede ejecutarse como un sistema independiente, sino que debe usarse con una aplicación que reciba, analize y almacene mensajes de registro en Elasticsearch. Muchos sitios están utilizando Logstash para esta tarea, y la configuración predeterminada de Kibana es compatible con Logstash. Además, Kibana espera que los mensajes de registro en la base de datos Elasticsearch tengan algunos campos creados por Logstash (por ejemplo, @timestamp y @message). Sin embargo, si otra aplicación está configurada para insertar mensajes de registro en la base de datos Elasticsearch con estos pares nombre-valor de campo, Kibana puede trabajar con datos de registro almacenados.
Para buscar mensajes de registro, Kibana admite la sintaxis completa de la consulta de Apache Lucene para todos los campos de mensaje. Una ventaja de Kibana sobre Graylog2 es el soporte para la creación de varios informes gráficos. Los informes se pueden crear en función de un campo de mensaje y un marco de tiempo seleccionados, ya sea para todos los mensajes o para algunos criterios de coincidencia de mensajes. Kibana admite la creación de gráficos circulares que reflejan la distribución de valores de campo, informes de análisis de tendencias e informes de recuento de valores de campo. Al seleccionar algún valor del formulario de informe, el usuario puede ir a los mensajes de registro relevantes. Los informes también se pueden crear directamente desde las búsquedas, por ejemplo, la consulta @ fields.srcip = 10.1.1. selecciona todos los mensajes donde el campo @ fields.srcip (dirección IP de origen) tiene el valor 10.1.1.1, mientras que la consulta:
@fields.srcip=10.1.1.1 | terms @fields.dstip
crea un gráfico circular sobre la distribución de los valores de @ fields.dstip (dirección IP de destino) para la fuente IP 10.1.1.1.
Como rsyslog tiene soporte para Elasticsearch desde 2012, se puede usar en lugar de Logstash para recibir y preparar datos de registro para Kibana. Las siguientes declaraciones de configuración rsyslog logran una puerta de enlace simple entre los mensajes syslog de BSD y Elasticsearch:
$ModLoad /usr/local/lib/rsyslog/omelasticsearch.s
$template Syslog2Json, "{\"@timestamp\":\"%timereported:::date-rfc3339%\", \"@message\":\"%msg:::json%\",\"@source\":\"unknown\",\"@type\":\"syslog\",\"@tags\":[], \"@fields\":{\"receptiontime\":\"%timegenerated:::date-rfc3339%\", \"host\":\"%HOSTNAME:::json%\",\"tag\":\"%syslogtag:::json%\"}}
$template SyslogIndex, "rsyslog-%timereported:1:10:date-rfc3339%"
daemon.* action(type="omelasticsearch" template="Syslog2Json" dynSearchIndex="on" searchIndex="SyslogIndex" server="localhost" bulkmode="on")
La primera instrucción carga el módulo de salida Elasticsearch para rsyslog. La segunda declaración define una plantilla llamada Syslog2Json, que convierte el mensaje de syslog de BSD al formato JSON. Los valores entre signos de porcentaje, como reportados en el tiempo, denotan campos extraídos del mensaje syslog, mientras que el sufijo ::: date date-rfc3339 convierte la marca de tiempo dada en formato RFC3339. Además, el sufijo ::: json después del nombre del campo significa que el campo está hecho compatible con JSON (por ejemplo, las comillas dobles deben escaparse con una barra diagonal inversa, ya que se utilizan como delimitadores en los registros JSON). El tercer extracto define un índice separado de Elasticsearch para cada día, que tiene el formato rsyslog-YYYY-MM-DD (por ejemplo, rsyslog- 2012-12-02). La cuarta instrucción coincide con todos los mensajes con la función daemon y los inserta en el índice syslog-YYYY-MM-DD de la base de datos Elasticsearch local. La declaración bulkmode = "on" habilita las inserciones masivas: en lugar de insertar cada mensaje de registro por separado, se inserta un mayor número de mensajes en un lote con una única operación de inserción que aumenta significativamente el rendimiento del mensaje.
Para evaluar el rendimiento de Logstash y rsyslog, se instalo Kibana con Elasticsearch en un nodo de Fedora Linux con 8 GB de memoria y un procesador Intel Core i5 650, y configuramos tanto rsyslog como Logstash en este nodo. Ambas soluciones se configuraron para insertar mensajes en Elasticsearch en modo bulk (para rsyslog, el tamaño del lote del mensaje era 16, mientras que para Logstash se usó un tamaño de lote de 100). Para la evaluación del rendimiento, se envio 100.000 mensajes syslog BSD sobre TCP al receptor, y medimos el tiempo de procesamiento de estos mensajes. Al final de cada prueba, se realizó una consulta a Elasticsearch para verificar que todos los mensajes estuviesen insertados correctamente en la base de datos. Se repitio esta prueba 100 veces para rsyslog y Logstash, eliminando todos los mensajes insertados entre ejecuciones de prueba consecutivas. Los resultados del experimento se presenta en la tabla. Para rsyslog, 100.000 mensajes se procesaron en un promedio de 17.066 segundos, produciendo una velocidad de procesamiento promedio de 5859.6 mensajes por segundo. En el caso de Logstash, la velocidad de procesamiento promedio fue de 1732.952 mensajes por segundo. En otras palabras, rsyslog puede insertar mensajes en Elasticsearch más de 3 veces más rápido que Logstash.

Durante la prueba, también descubrimos una característica molesta de Logstash: para inserciones masivas, los mensajes se acumulan en un búfer que se vacía solo cuando está lleno. Por lo tanto, los mensajes de registro pueden permanecer en el búfer durante largos períodos de tiempo si el búfer aún contiene algo de espacio libre. Por el contrario, rsyslog implementa un algoritmo de inserción masiva más eficiente que no deja mensajes sin procesar pendientes en la memoria.