La recuperación de desastres (DR, Disaster Recovery) consiste en prepararse y recuperarse de un desastre. Cualquier evento que tenga un impacto negativo en la continuidad del negocio o en las finanzas de una empresa podría considerarse un desastre. Esto incluye fallos hardware o software, cortes de red o de energía, daños físicos, incendios o inundaciones, errores humanos o algún otro evento significativo.
Para minimizar el impacto de un desastre, las empresas invierten tiempo y recursos para planificar y preparar, capacitar empleados, documentar y actualizar procesos. La cantidad de inversión para la planificación de DR para un sistema en particular puede variar dramáticamente dependiendo del coste de una interrupción potencial. Las empresas que tienen entornos físicos tradicionales normalmente deben duplicar su infraestructura para garantizar la disponibilidad de capacidad adicional en caso de un desastre. La infraestructura debe ser adquirida, instalada y mantenida de modo que esté lista para soportar los requisitos de capacidad anticipados.
A lo largo del post describiremos las mejores prácticas para mejorar los procesos de recuperación ante desastres, desde inversiones mínimas hasta disponibilidad a gran escala y tolerancia a fallos, mostrando cómo podemos utilizar los servicios de AWS para reducir costes y garantizar la continuidad del negocio durante un evento de Disaster Recovery, pero antes de nada, tendremos que familiarizarnos con dos terminos que ya vimos:
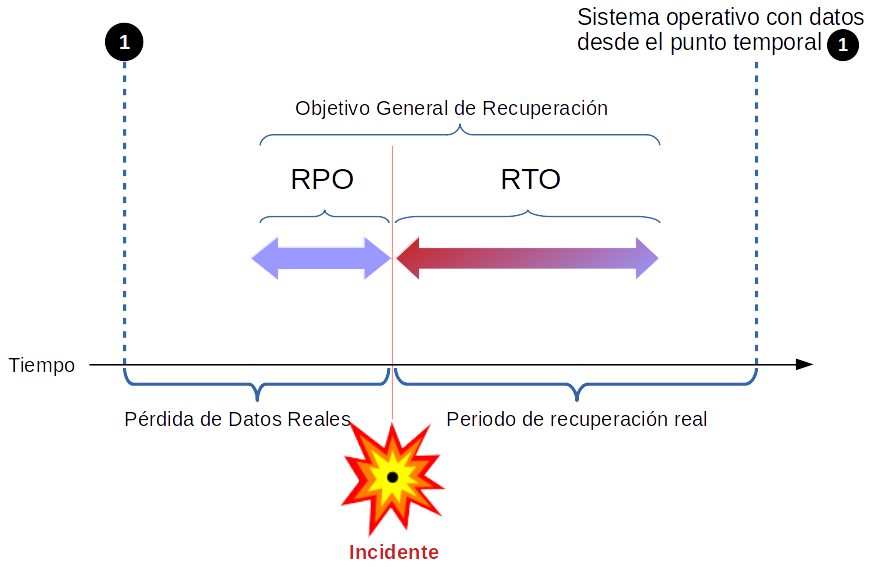
Recovery Time Objective (RTO) : Tiempo que toma después de una interrupción para restaurar un proceso de negocio a su nivel de servicio, según lo define el acuerdo de nivel operacional (OLA). Por ejemplo, si ocurre un desastre a las 12:00 y el RTO es de ocho horas, el proceso de DR debe restaurar el proceso de negocios al nivel de servicio aceptable para las 20:00.
Recovery Point Objective (RPO): La cantidad aceptable de pérdida de datos medida en el tiempo. Por ejemplo, si ocurre un desastre a las 13:00 y el RPO es de una hora, el sistema debe recuperar todos los datos que estaban en el sistema antes de las 12:00. La pérdida de datos abarcará solo una hora, entre las 12:00 y las 13:00.
Prácticas de inversión en Disaster Recivery
Un enfoque tradicional de DR implica diferentes niveles de duplicación de datos e infraestructura. Los servicios empresariales críticos se configuran y mantienen en esta infraestructura y se prueban a intervalos regulares (O almenos se debería, aunque ya sabemos la realidad). La ubicación del entorno de recuperación de desastres y la infraestructura de origen deben estar a una distancia física significativa aparte para garantizar que el entorno de recuperación de desastres esté aislado de las fallas que podrían afectar el sitio de origen.
Como mínimo, la infraestructura que se requiere para soportar el entorno duplicado debe incluir lo siguiente:
- Instalación de la infraestructura, incluida la potencia y el enfriamiento.
- Seguridad para garantizar la protección física de los activos.
- Capacidad adecuada para escalar el entorno.
- Soporte para reparar, reemplazar y actualizar la infraestructura.
- Acuerdos contractuales con un proveedor de servicios de Internet (ISP) para proporcionar conectividad a Internet (Si somos ISP, debemos tener en cuenta que puede ser nuestra propia red la afectada, necesitando estos acuerdos si o si con otro ISP.)
- Infraestructura de red, como cortafuegos, enrutadores, conmutadores y balanceadores de carga.
- Suficiente capacidad de servidor para ejecutar todos los servicios de misión crítica, incluidos los dispositivos de almacenamiento para los datos de respaldo,
y servidores para ejecutar aplicaciones y servicios backend, como autenticación de usuario, Sistema de nombres de dominio (DNS), (DHCP), monitorización ...
Servicios AWS que necesitaras para tu Disaster Recovery
Las piezas de infraestructura esenciales incluyen DNS, funciones de red y varias características de Amazon Elastic Compute Cloud (Amazon EC2) que vamos a describir.
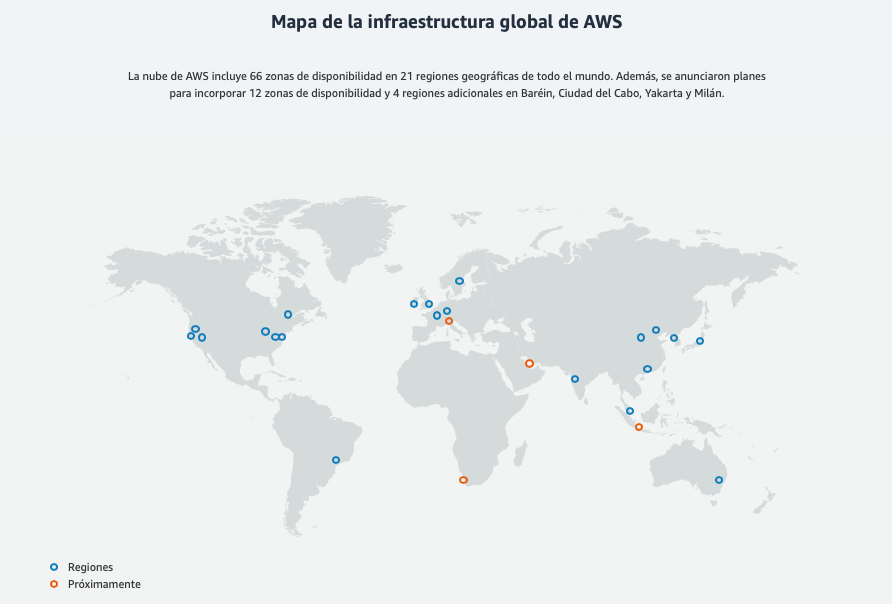
Los servicios web de Amazon están disponibles en varias regiones del mundo, por lo que podremos elegir la ubicación más adecuada para nuestro DR. AWS tiene múltiples regiones de propósito general en América, EMEA y Asia Pacífico a las que cualquier persona con una cuenta de AWS puede acceder.
Almacenamiento
- Amazon Simple Storage Service (Amazon S3) proporciona una infraestructura de almacenamiento altamente duradera diseñada para el almacenamiento de datos primarios y de misión crítica. Los objetos se almacenan de forma redundante en múltiples dispositivos a través de múltiples instalaciones dentro de una región, diseñada para brindar una capacidad de lectura de 99.999999999% (119s) .AWS proporciona protección adicional para la protección y el archivado a través del control de versiones en Amazon S3, autenticación multifactor AWS (AWS MFA), AWS Identity and Access Management (IAM) . IAM es un servicio web que nos ayudará a controlar de forma segura el acceso a los recursos de AWS controlando quien está autenticado (ha iniciado sesión) y autorizado (tiene permisos) para utilizar recursos.
- Amazon Glacier proporciona almacenamiento de bajo costo para archivar y respaldar datos. Los objetos (o archivos, como se conocen en Amazon Glacier) están optimizados para el acceso poco frecuente, para lo cual los tiempos de recuperación de varias horas son adecuados (Importante este dato). Amazon Glacier está diseñado para tener la misma durabilidad que la estrella s3. Y lo más sorprendente, a un coste de 0,004$/Gb.
- AWS Import / Export acelera el traslado de grandes cantidades de datos dentro y fuera de AWS mediante el uso de dispositivos de almacenamiento portátiles para el transporte. AWS Import / Export omite Internet y transfiere sus datos directamente dentro y fuera de los dispositivos de almacenamiento a través de la red interna de alta velocidad de Amazon. Para conjuntos de datos de tamaño significativo, la importación / exportación de AWS suele ser más rápida que la transferencia de Internet y más rentable que la actualización de su conectividad. Puede usar Importar / Exportar de AWS para migrar datos dentro y fuera de los depósitos de Amazon S3 y las bóvedas de Amazon Glacier o en las instantáneas de Amazon EBS.
- AWS Snowball (Uno de esos inventos sencillos que pocos han pensado y que tiene mucha lógica), acelera el traslado de grandes cantidades de datos dentro y fuera de AWS mediante el uso de dispositivos de almacenamiento portátiles adaptados para su transporte. Omite Internet y transfiere sus datos directamente dentro y fuera de los dispositivos de almacenamiento. Para conjuntos de datos de tamaño significativo, la importación / exportación de AWS suele ser más rápida que la transferencia de Internet y más rentable que la actualización de la conectividad.
Computación
- Amazon Elastic Compute Cloud (Amazon EC2) proporciona capacidad de cálculo redimensionable en cloud. En cuestión de minutos, podemos crear instancias de Amazon EC2, que son máquinas virtuales sobre las que tenemos control total. En el contexto de DR, la capacidad de crear rápidamente máquinas virtuales que podemos controlar es fundamental, y por ello, nos centramos en los aspectos de Amazon EC2 que son relevantes para la recuperación ante desastres.
Las imágenes de máquina de Amazon están preconfiguradas con sistemas operativos, y algunas preconfiguradas con aplicaciones, así cómo configurar nuestros propias máquinas. En el contexto de DR, se recomienda encarecidamente configurar e identificar nuestras propias máquinas para que podamos iniciar las mismas como parte de nuestro procedimiento de recuperación. Dichas AMIs deben estar preconfiguradas con el sistema operativo que elijamos, más las piezas apropiadas de la pila de aplicaciones disponibles.
Ahora un tema importante: Si usamos Amazon EC2 VM Import Connector nos permite importar imágenes de máquinas virtuales desde nuestro entorno existente a instancias de Amazon EC2, un punto que puede ser clave el nuestro PCN (Plan de Continuidad de Negocio)
Redes
Cuando se trata de un desastre, es muy probable que tengamos que modificar nuestra configuración de la red, almenos tendremos que apuntarlo al nuevo site. AWS ofrece varios servicios y funciones que nos permiten administrar y modificar la configuración de red.
- Amazon Route 53 es un servicio web de Sistema de nombres de dominio (DNS), como ya nos iba adelantando ese número 53 :), en alta disponibilidad y escalable. Brinda a los desarrolladores y empresas una forma confiable y rentable de encaminar a los usuarios a las aplicaciones. Amazon Route 53 incluye una serie de capacidades globales de balanceo de carga (que pueden ser efectivas cuando se trata de escenarios de DR, como las comprobaciones de estado del DNS) y la capacidad de conmutación por error entre múltiples puntos finales e incluso sitios web estáticos alojados en Amazon S3.
Las direcciones IP elásticas son direcciones IP estáticas diseñadas para la computación dinámica en la nube. Sin embargo, a diferencia de las direcciones IP estáticas tradicionales, las direcciones IP elásticas nos permiten enmascarar los fallos de la instancia o la Zona de disponibilidad mediante la reasignación programática de sus direcciones IP públicas a las instancias de nuestra cuenta en una región particular. Para DR, podemos pre-asignar algunas direcciones IP para los sistemas más críticos (Amazon sólo nos deja 5 y más con justificación de necesidad) para que nuestras direcciones IP ya sean conocidas antes de que ocurra un desastre. Esto puede simplificar la ejecución del plan de DR. - Elastic Load Balancing distribuye automáticamente el tráfico de aplicaciones entrantes en varias instancias de Amazon EC2. Nos permite lograr una mayor tolerancia a fallos en nuestras aplicaciones al proporcionar la capacidad de equilibrio de carga que se necesitamos. Al igual que podemos pre-asignar las direcciones IP elásticas, podemos asignar previamente el balanceador de carga para que el DNS ya sea conocido, simplificando la ejecución del plan DR.
- Amazon Virtual Private Cloud (Amazon VPC) nos permite provisionar una sección privada y aislada de la cloud AWS donde podemos iniciar los recursos de AWS en una red virtual que definamos. Teniendo así control completo sobre el entorno de red virtual, incluida la selección del rango de direcciones IP, la creación de subredes y la configuración de tablas de rutas y puertas de enlace de red. Esto nos permite crear una conexión VPN entre nuestro datacenter corporativo y la VPC, y aprovechar la nube de AWS como una extensión de nuestro centro de datos corporativo. En el contexto de DR, puedemos usar Amazon VPC para extender nuestra topología de red existente hacia la cloud, siendo especialmente apropiado para recuperar aplicaciones empresariales que normalmente están en la red interna.
Bases de datos
- El Servicio de bases de datos relacionales de Amazon (Amazon RDS) facilita la configuración, el funcionamiento y la escala de una base de datos relacional en cloud. Podemos usar Amazon RDS en la fase de preparación del DR para guardar los datos críticos en una base de datos que ya se esté ejecutando, o en la fase de recuperación para ejecutar la base de datos de producción. De igual forma y pensando en el plan DR, podemos crear instantánea de los datos en distintas regiones.
- AmazonDynamoDB es un servicio rápido y totalmente administrado de bases de datos NoSQL que lo hace simple y rentable para almacenar y recuperar cualquier cantidad de datos y atender cualquier nivel de tráfico de solicitudes. Tiene un rendimiento muy robusto y una latencia de milisegundos de un solo dígito. Durante la fase de recuperación de Disaster Recovery, podemos escalar sin problemas en cuestión de minutos con un solo clic o llamada a la API.
- Amazon Redshift es un servicio de almacenamiento de datos rápido, totalmente administrado, a escala de petabytes que hace que sea simple y rentable analizar de manera eficiente todos nuestros datos utilizando sus herramientas de inteligencia empresarial existentes. Podemos usar Amazon Redshift en la fase de preparación del DR para capturar una instantánea del almacén de datos para almacenarlo de manera duradera en Amazon S3 . De esta forma, durante la fase de recuperación del DR, puede restaurar rápidamente nuestro almacenamiento de datos.
Escenarios de Disaster Recovery con AWS
La siguiente figura muestra un espectro de los cuatro escenarios que vamos a ver, organizado por la rapidez con que un sistema puede estar disponible para los usuarios después de un evento de recuperación ante desastres.
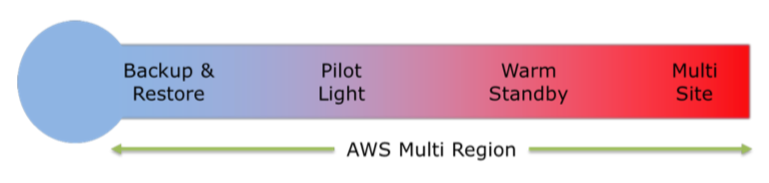
Backup y restauración
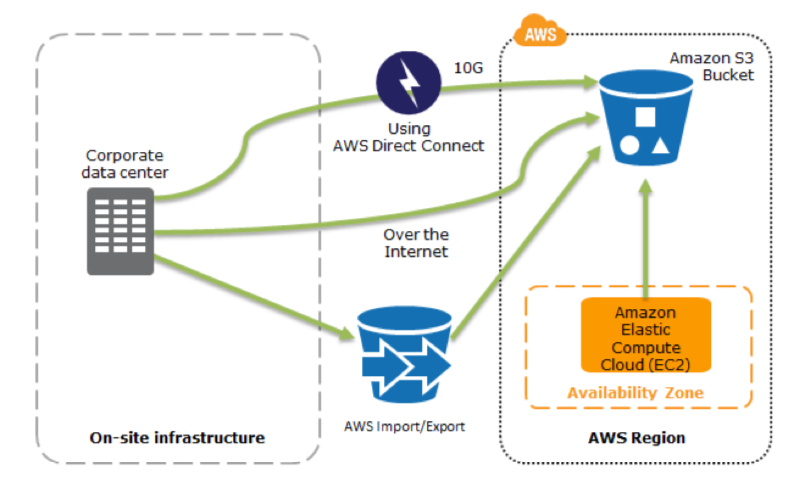
En la mayoría de los entornos tradicionales, los datos se respaldan en cinta y se envían fuera del sitio (Por norma general). Si utilizamos este método, puede llevar mucho tiempo restaurar nuestros sistemas en caso de una interrupción o desastre. Amazon S3 es un destino ideal para la copia de seguridad de datos que pueden ser necesarios rápidamente para realizar una restauración.
La transferencia de datos hacia y desde Amazon S3 generalmente se realiza a través de la red y, por lo tanto, es accesible desde cualquier ubicación. Existen muchas soluciones de respaldo comerciales y de código abierto que se integran además de poder usar AWS Import / Export para transferir conjuntos de datos muy grandes enviando dispositivos de almacenamiento directamente a AWS (Teniendo en cuenta que esto deberíamos hacerlo previamente). También existe Amazon Glacier, que tiene el mismo modelo de durabilidad que Amazon S3. Amazon Glacier es una alternativa de bajo coste (Desde $ 0.01 GB/mes) en la que ambas se pueden usar en conjunto para producir una solución de respaldo escalonada.
AWS Storage Gateway permite que se copien instantáneamente instancias de los volúmenes de datos locales en Amazon S3 para realizar copias de seguridad. Posteriormente, podemos crear volúmenes locales o volúmenes de Amazon EBS a partir de estas instantáneas. Los volúmenes almacenados en caché nos permite almacenar nuestros datos primarios en Amazon S3, pero mantenemos los datos de acceso frecuente para un acceso de baja latencia.
Todos estos sistemas de AWS pueden ser usados como reemplazo de la tradicional copia de seguridad de cinta magnética.
La copia de seguridad de nuestros datos es solo la mitad de la historia. Si ocurre un desastre, deberemos recuperar los datos de manera rápida y confiable, asegurandonos que los sistemas estén configurados para retener y proteger los datos. Y algo muy importante que se nos suele olvidad: debemos probar los procesos de recuperación de datos.
Pasos clave para la copia de seguridad y restauración:
- Seleccionar una herramienta o método apropiado para hacer una copia de seguridad de los datos en AWS.
- Asegurarnos de tener una política de retención adecuada para nuestros datos.
- Asegurarnos de que existan medidas de seguridad adecuadas para los datos, incluidas las políticas de cifrado y acceso.
- Probar regularmente la recuperación de estos datos y la restauración de nuestro sistema.
Pilot Light como concepto de rápida recuperación ante desastres
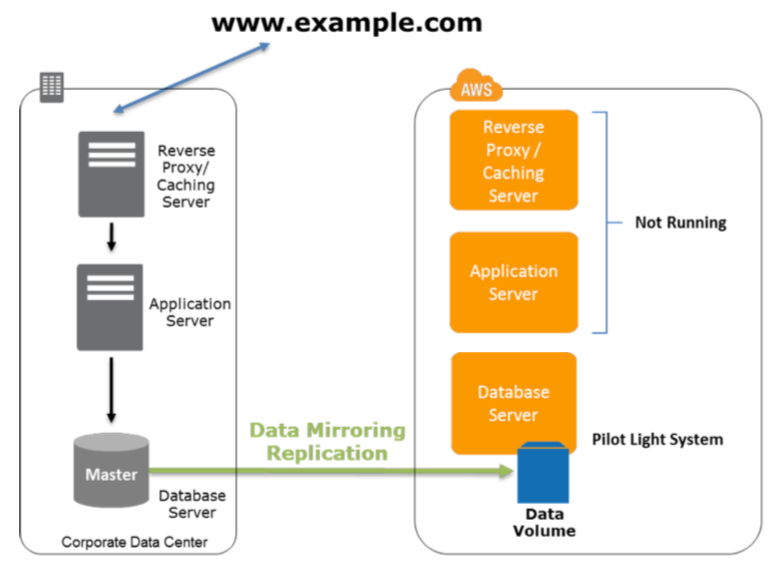
El “pilot light” o luz de piloto a menudo se usa para describir un escenario de DR en el que una versión mínima del entorno siempre se ejecuta en cloud o esta disponible. La idea de pilot light es una analogía que proviene del calentador de gas. En un calentador de gas, una pequeña llama que siempre está encendida puede encender rápidamente todo el quemador para calentar una casa.
Este escenario es similar a un escenario de copia de seguridad y restauración. Por ejemplo, con AWS podemos mantener un pilot light configurando ejecutando los elementos centrales más críticos en AWS. En el momento de la recuperación del desastre, podemos provisionar rápidamente un entorno de producción a gran escala sobre dicho núcleo crítico del pilot light.
Los elementos de infraestructura del pilot light generalmente incluyen los servidores de base de datos, que estarían replicados en Amazon EC2 o Amazon RDS. También puede haber otros datos críticos fuera de la base de datos que deben replicarse en AWS. Para provisionar el resto de la infraestructura para restaurar servicios críticos para la empresa, normalmente tendremos algunos servidores preconfigurados agrupados como Amazon Machine Images (AMI), que están listos para iniciarse en cualquier momento. Al comenzar la recuperación, las instancias de estas AMI aparecerán rápidamente con su función predefinida (por ejemplo, servidor web o de aplicaciones) dentro de la implementación. Desde el punto de vista de la red, hay dos opciones principales para la provisión:
- Utilizar Elastic IPs que puedan asignarse y identificarse previamente en la fase de preparación del DR, y asociarlas con las instancias.
- Utilizar Elastic Load Balancing (ELB) para distribuir el tráfico a varias instancias. Luego actualizaríamos los registros DNS para apuntar a las instancias de Amazon EC2 o apuntariamos al balanceador de carga utilizando un CNAME.
Para sistemas menos críticos, podemos asegurarnos de tener los paquetes de instalación y la información de configuración disponibles en AWS, por ejemplo, en forma de una instantánea de Amazon EBS. Esto acelerará la configuración del servidor de aplicaciones, ya que podemos crear rápidamente múltiples volúmenes en múltiples zonas de disponibilidad para adjuntarlos a instancias de Amazon EC2. Luego podemos instalar y configurar los sistemas, por ejemplo, utilizando el método de copia de seguridad y restauración.
El método Pilot ligth, como hemos visto, brinda un tiempo de recuperación más rápido que el método de copia de seguridad y restauración porque las piezas centrales del sistema ya se están ejecutando y se mantienen actualizadas continuamente. A todo esto, tenemos que tener en cuenta, que AWS nos permite automatizar el provisionamiento y la configuración de los recursos de infraestructura, lo que nos brindará una gran ventaja y recorte del RTO.
Fase de preparación de Pilot ligth
En esta fase, se debe replicar los datos que cambian regularmente hacia Pilot Ligth, el pequeño núcleo alrededor del cual se iniciará el entorno completo en la fase de Disaster Recovery. Los datos actualizados con menor frecuencia, como los sistemas operativos y las aplicaciones, pueden actualizarse periódicamente (Dependiendo del sistema) y almacenarlos como AMIs.
Pasos clave para la preparación:
- Configurar las instancias de Amazon EC2 para replicar o duplicar datos.
- Asegurarnos que tenemos los paquetes de software personalizados compatibles y disponibles en AWS.
- Crear y mantener AMIs de servidores clave donde se requiera una recuperación rápida.
- Ejecute regularmente estos servidores, probar y aplicar las actualizaciones de software y los cambios de configuración.
- Una vez armado el plan, debemos considerar automatizar el aprovisionamiento de recursos de AWS.
Fase de recuperación con Pilot ligth
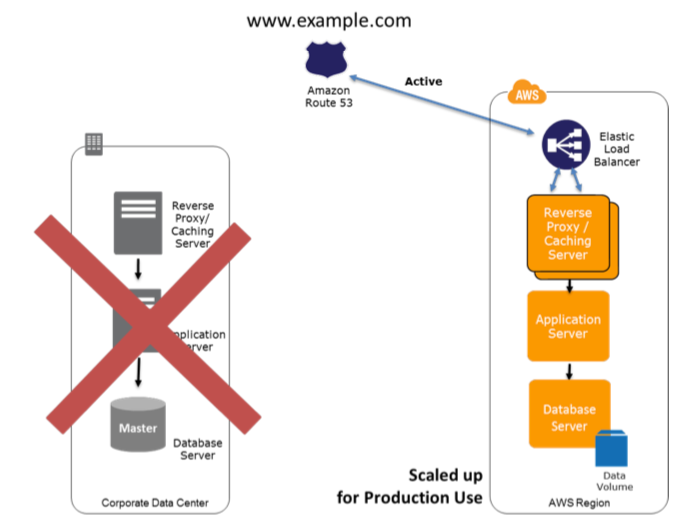
Para recuperar el resto de entorno alrededor de la Pilot Ligth (Esa otra parte de la imagen anterior que no esta corriendo, y engranarla con el resto de piezas) podemos iniciar nuestros sistemas desde las AMIs en cuestión de minutos con los tipos de instancia apropiados. Para los servidores de datos dinámicos, podemos cambiar el tamaño para manejar volúmenes de producción según necesitemos o agregar nuevas capacidades. El escalado horizontal a menudo es el enfoque más rentable y escalable para agregar capacidad a un sistema. Por ejemplo, podemos agregar más servidores web en las horas punta (Algo por ejemplo a tener en cuenta si emites partidos de football y es el partidazo). Sin embargo, también podemos elegir tipos de instancia de Amazon EC2 más grandes y, por lo tanto, escalar verticalmente para aplicaciones con bases de datos relacionales. Desde una perspectiva de red, cualquier actualización de DNS requerida se puede hacer en paralelo.
Después de la recuperación, debemos asegurarnos de que la redundancia se restablezca lo antes posible. Es poco probable que falle el entorno de recuperación ante desastres poco después de que falle el entorno de producción (Si es así, nos ha mirado un tuerto), pero debemos tener en cuenta este riesgo.
Pasos clave para la recuperación:
- Iniciar las instancias de la aplicación Amazon EC2 desde las AMIs personalizadas.
- Cambiar el tamaño de las instancias existentes de la base de datos / almacén de datos para procesar el aumento del tráfico.
- Instancias adicionales de bases de datos / almacenes de datos para proporcionar la capacidad de recuperación del sitio DR.
- Cambiar el DNS para apuntar a los servidores Amazon EC2.
- Instalar y configurar cualquier sistema no basado en AMIs, si es posible y como hemos comentado antes, de forma automatizada.
Solución Warm Site en AWS
El término "sitio caliente" se utiliza para describir un escenario de recuperación ante desastres en el que una versión reducida del entorno, totalmente funcional, siempre se ejecuta en cloud (Recordando que el post es sobre AWS, si no, seria en otro entorno paralelo). Una solución de espera en caliente extiende los elementos y el Pilot Ligth y disminuye aún más el tiempo de recuperación porque algunos servicios siempre están corriendo.
Al identificar los sistemas críticos para el negocio, podemos duplicar completamente estos sistemas en AWS y tenerlos siempre encendidos. Esta solución no está diseñada para llevar una carga de producción completa, pero es completamente funcional. En caso de un desastre, el sistema se amplía rápidamente para manejar la carga de producción. En AWS, esto se puede hacer agregando más instancias al balanceador de carga y redimensionando los servidores de pequeña capacidad para que se ejecuten en tipos de instancia de Amazon EC2 más grandes, es preferible escalar horizontalmente mejor que de forma vertical.
Fase de preparación del Warm Site
En la figura, observamos una solución in situ en nuestro CPD y una solución en AWS ejecutandose en el otro lado.
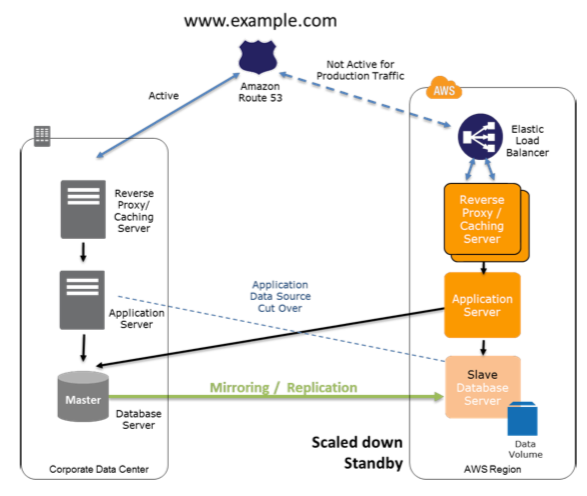
Pasos clave para la preparación:
- Configurar las instancias de Amazon EC2 para replicar o duplicar datos.
- Crear y mantener las AMIs.
- Ejecutar la aplicación utilizando una huella mínima de instancias en Amazon EC2 o infraestructura de AWS.
- Parchear y actualizar el software y los archivos de configuración de acuerdo con nuestro entorno.
Recuperación del Warm Site en AWS
En caso de fallo del sistema de producción, el entorno en espera se ampliará para la carga de producción, y los registros DNS se cambiarán para enrutar todo el tráfico a AWS.
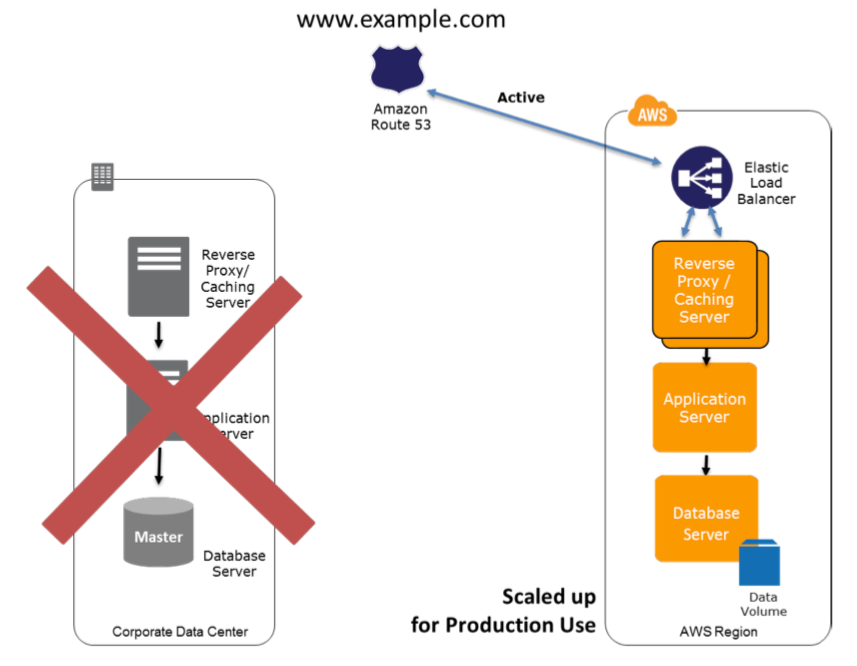
Pasos clave para la recuperación:
- Aumentar el tamaño de las flotas de Amazon EC2 en servicio con el balanceador de carga escalando horizontalmente.
- Iniciar las aplicaciones en tipos de instancias Amazon EC2 más grandes según sea necesario, escalando verticalmente.
- Cambiar manualmente los registros DNS o usar la comprobación de estado automatizadas de Amazon Route 53 para que todo el tráfico se enrute al entorno de AWS.
- Considerar usar Auto Scaling para ajustar el tamaño o acomodar la carga aumentada.
- Agregar o ampliar la base de datos.
Solución MultiSite implementada en AWS y en CPD
Una solución MultiSite se ejecuta en AWS, así como en nuestra infraestructura in situ existente en el CPD en este caso, con una configuración activo-activo. El método de replicación de datos que emplea estará determinado por el punto de recuperación que elijamos (RTO - RPO).
Podemos usar un servicio DNS que admita enrutamiento ponderado (Dicho así, uno dice ... ¿que es esto?, pero si os lo cambio por Round Robin, la cosa cambia), como Amazon Route 53, para enrutar el tráfico de producción a diferentes sitios que brinden el mismo servicio de aplicación. Una proporción de tráfico irá a la infraestructura en AWS, y el resto irá a la infraestructura CPD.
En un desastre in situ en CPD, podemos ajustar la ponderación del DNS y enviar todo el tráfico a los servidores de AWS. La capacidad del servicio de AWS se puede aumentar rápidamente para manejar toda la carga de producción. Se puede usar Amazon EC2 Auto Scaling para automatizar este proceso y acortar tiempos.
El coste de este escenario está determinado por cuánto tráfico de producción se maneja en AWS durante la operación normal. De esta forma, en la fase de recuperación, se pagará solo por lo que se usa durante el tiempo en que se requiere el entorno DR escalado completamente.
Fase de preparación MultiSite en AWS
La siguiente figura muestra el enrutamiento Round Robin del DNS Amazon Route 53 para enrutar una parte del tráfico a AWS. La aplicación en AWS podría acceder a las fuentes de datos en el sistema de producción in situ. Los datos se replican o reflejan en la infraestructura de AWS al estar activo-activo, en diferencia con los entornos anteriores.
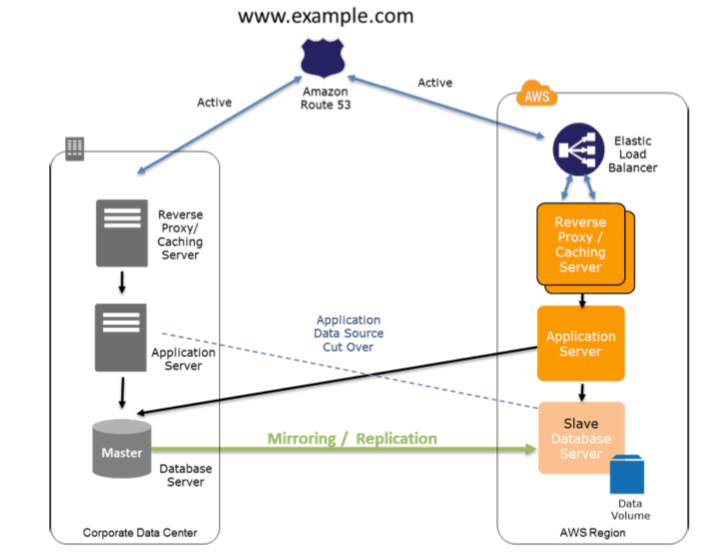
Pasos clave para la preparación del entorno Activo-Activo AWS:
- Configura el entorno AWS para duplicar el entorno de producción in situ.
- Configura lagestión Round Robin en el DNS, o la tecnología de enrutamiento de tráfico similar, para distribuir las solicitudes/peticiones a ambos sitios. Configura la conmutación por error automática.
Fase de recuperación Activo-Activo AWS
La figura muestra el cambio en el enrutamiento del tráfico en caso de un desastre en el sitio. El tráfico se corta y redirige a la infraestructura de AWS mediante la actualización del DNS, y todo el tráfico y las consultas de datos se realizan sobre la infraestructura de AWS.
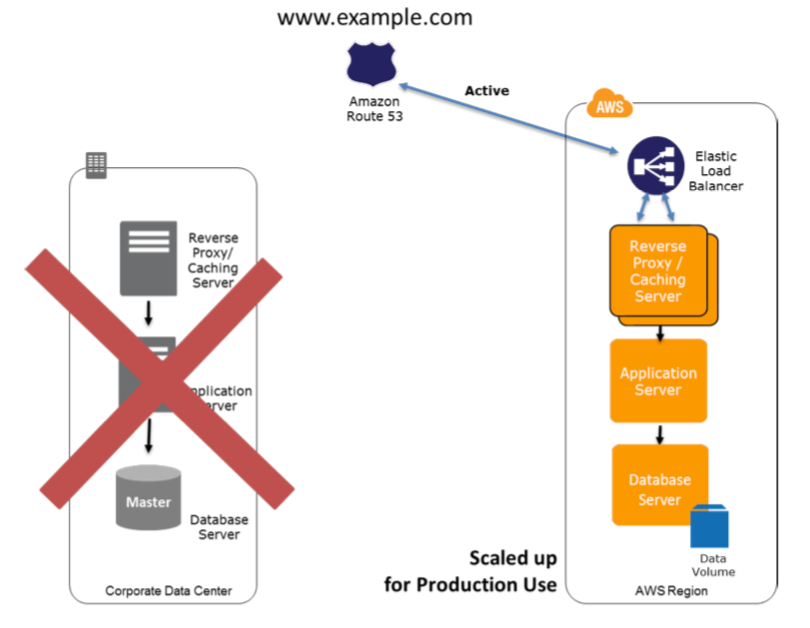
Recuperación Disaster Recovery Activo-Activo AWS :
- De forma manual o mediante la conmutación por error del DNS(Que sería lo lógico), cambiamos la ponderación del DNS para que todas las solicitudes se envíen a AWS.
- Tenemos que tener una lógica de aplicación para la conmutación por error para usar los servidores de bases de datos locales de AWS en la consultas.
- Muy muy muy importante. Considera usar Auto Scaling para ajustar automáticamente el tamaño de las máquinas AWS.
Réplica de datos
Cuando replicamos datos en una ubicación remota, debemos considerar:
- Distancia entre sitios: las distancias más grandes generalmente están sujetas a más latencia o fluctuación.
- Ancho de banda disponible: La amplitud y variabilidad de las interconexiones.
- Velocidad de datos requerida por la aplicación: la velocidad de datos debe ser inferior al ancho de banda disponible.
- Tecnología de replicación: La tecnología de replica debe ser paralela (para que podamos usar la red eficazmente). Similar a la típica linea de Backup en sistemas (Servicio-Gestión-Backup).
Hay dos enfoques principales para replicar datos:
- Replicación sincrónica : Los datos se actualizan atómicamente en múltiples ubicaciones. Esto pone una dependencia en el rendimiento y la disponibilidad de la red. Por ejemplo, cuando se implementa en modo Multi-AZ, Amazon RDS usa replicación sincrónica para duplicar datos en una segunda zona de disponibilidad. Esto garantiza que los datos no se pierdan si la zona de disponibilidad primaria no está disponible.
- Replicación asincrónica: Los datos no se actualizan atómicamente en varias ubicaciones. Se transfiere según lo permita el rendimiento y la disponibilidad de la red, y la aplicación continúa escribiendo datos que aún podrían no estar completamente replicados. Muchos sistemas de bases de datos admiten la replicación de datos asíncrona. Esto es aceptable en muchos escenarios, por ejemplo, como fuente de respaldo o informes / casos de solo lectura.
Conclusión
Existen muchas opciones y variaciones para un plan de Disaster Recovery. Hemos visto los escenarios comunes, que van desde simples copias de seguridad y restauración hasta soluciones de múltiples sitios con tolerancia a fallos. AWS brinda un control preciso y muchos componentes básicos para construir una solución DR adecuada (No lo hemos comentado, pero lo cierto es que podriamos hacer lo mismo en Azure, me lo apunto para otro Post), dados nuestros objetivos DR (RTO y RPO) y nuestro presupuesto (La ventaja, pagamos por lo que usamos a diferencia de los antiguos planes), una ventaja clave para un DR, donde se necesita una infraestructura significativa de una forma rápida, pero solo en caso de un desastre.
En mi opinión, es la mejor forma de empezar a implementar Clouds hibridas, entre nuesto CPD y AWS, si aún somo de los que no confiamos en la Cloud. Es tan sencillo como hacer un TCO exahustivo de vuestro plan de recuperación ante desastres y barajar la opción de migrar parte de vuestros sistemas a la nube.